이미지 분류, 나아가 컴퓨터 비전 분야에 있어 트랜스포머 아키텍처의 사용은 매우 제한적이었다. 자연어 처리 분야에서는 트랜스포머를 기반으로 등장한 BERT나 GPT 모델들이 game-changer 역할을 하고 있지만, 비전에서는 attention이 합성곱 신경망(convolutional network)과 함께 적용되거나 전체 구조를 유지하면서 합성곱 신경망의 특정 component를 대체하는 부분적인 적용에 그쳤다. ViT는 비전 task에 있어서 CNN에 대한 의존은 더 이상 필요하지 않으며, 이미지 임베딩 벡터에 직접 적용되는 attention은 그 자체만으로도 이미지 분류 작업을 잘 수행할 수 있다고 보여준다.
ViT는 이미지 patch별 임베딩 벡터를 추출한 이후 트랜스포머 모델을 통과시켜 최종 예측값을 출력하기 때문에 트랜스포머란 무엇인지에 대한 사전 지식이 필요하다. 이에 대한 내용은 [DL] Attention 파헤치기 - Seq2Seq부터 Transformer까지 (1) 포스트와 [DL] Attention 파헤치기 - Seq2Seq부터 Transformer까지 (2) 포스트에 걸쳐 다루었으니 참고!
논문은 이쪽에서 확인: https://arxiv.org/abs/2010.11929

0. Why Transformers?
레이어를 깊게 쌓는 기존의 방식에서 트랜스포머 아키텍처의 적용으로 shift하는 이유에 대해 먼저 서술하려 한다.
- Global operation (convolution complementarity)
- Low computational cost, High accuracy
- Better connection of visuals and language
CNN 레이어는 커널 윈도우를 통해 정보를 압축해나가며 general answer를 탐색하기 때문에, 인접 픽셀 간의 관계만 모델링한다는 점에서 local operation이다. 이 구조는 일반적인 분류 작업에서는 좋은 성능을 발휘할 수 있지만 멀리 떨어져 있는 픽셀 간의 관계를 고려하기 어려워 이미지 전체의 정보를 통합하기 위해서는 다수의 레이어를 통과해야만 한다. 반면 트랜스포머는 모든 픽셀(단어로 치면 토큰) 간의 관계를 attention을 통해 모델링하기 때문에 global operation이라고 할 수 있다(자연어 처리에서 트랜스포머 아키텍처를 사용하면 모든 토큰과 토큰 사이의 조합에 대한 attention score을 구할 수 있다는 것을 생각해보면 쉽다, can extract all the information we need from the input and its inter-relations). 물론 naive하게 적용시키면 연산량이 이미지 크기에 비례해 어마어마하게 커지기 때문에(quandratic) ViT에서는 이미지를 쪼개 그 작은 이미지들 간 self-attention을 수행하는 방식으로 변형했다.
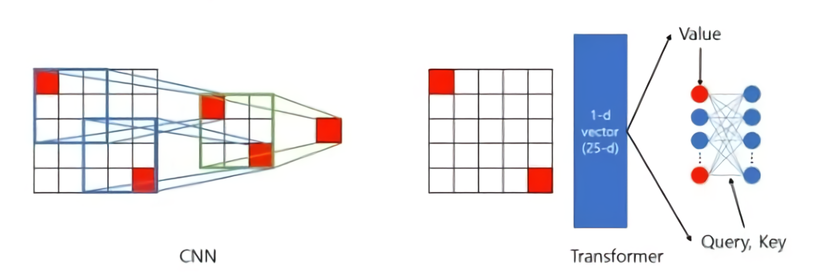
하나의 이미지를 subset인 patch로 나눈 다음(ex: 16x16 픽셀) 각 patch들끼리에 대한 self-attention을 계산하는 것은 연산량을 줄이고 memory-efficiency를 대폭 상승시켜주는 결과를 낳는다. 논문 본문에 의하면 타 State-of-art 모델과 같은 성능을 약 15분의 1 계산 비용만으로 얻을 수 있다고 한다.
마지막으로 트랜스포머의 이미지 분야에서의 사용은 자연어 처리 분야와 비전 분야를 더 가깝게 만들었다. 이전의 비전 분야에서는 보통 수십 또는 수백 개의 object category만 다루었지만, 해당 transfer는 이후 텍스트와 이미지의 연결다리가 되는 선구적인 작업(ex. CLIP과 DALL-E 등 AI image generator from text)의 시작점이 되었다고 볼 수 있다.
하나 제약이 있다면 ViT는 대규모의 데이터셋으로 pre-trained 되지 않는 이상 좋은 성능을 보여주기 어렵다는 것이다. 이는 inductive bias의 부재(정확히 말하면 '거의 없다'에 가까움) 때문인데, 하나의 레이어로 전체 이미지 정보를 통합할 수 있다는 global operation의 장점이자 단점이라고 할 수 있다. ViT의 self-attention 레이어의 경우 완전히 global하게 취급되기 때문에 2차원의 지역적인 정보를 유지할 수 없게 된다. 따라서 모델의 자유도는 높지만 주어지지 않은 입력에 대해 좋은 예측을 내놓기 어렵다(Google에서는 JFT300M이라는 공개되지 않은 대규모 데이터셋으로 학습시킴으로써 장점으로 승화시켰다. 다만 fine-tuning을 위한 데이터셋 확보가 어렵다면 성능은 보장 못함).
1. Introduction & Architecture
위에 벌써 patch 얘기를 꺼내버렸지만ㅋㅋ... 한 줄 요약하자면 입력 이미지를 여러 개의 patch로 쪼개, 각 patch를 벡터로 임베딩하는 과정을 거쳐 트랜스포머 인코더에 넣어준다. 그 뒤 classifier을 붙여 분류 task를 수행할 수 있도록 학습을 시키는 것이다.
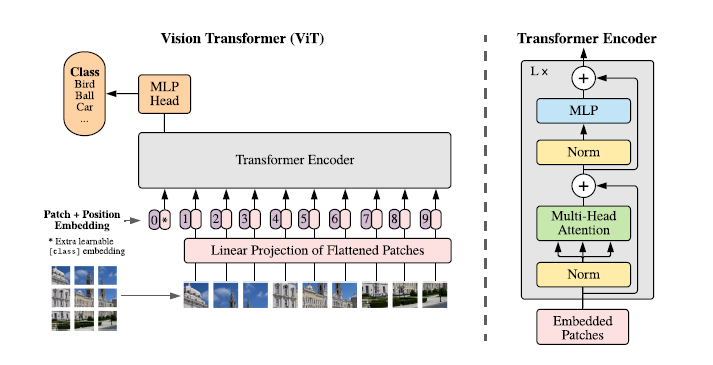
총 네 가지 단계로 나누어 설명해보겠다.
1-1. Patch embedding
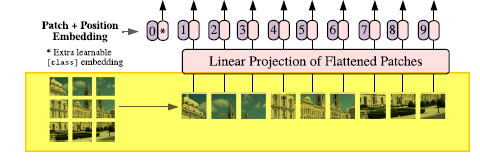
자연어 처리에 있어 트랜스포머의 인풋을 어떻게 처리했나 상기해보자. 문장(혹은 문단, sequence of words)을 단어 단위로 쪼개 토큰으로 만들고, 토큰의 임베딩 벡터에 postitional encoding 값을 더해주어 모델의 최종 입력을 정의했다.
ViT도 마찬가지로 첫 번째 단계에서 1차원의 토큰 임베딩 벡터를 입력으로 받아야 한다. 이를 위해 \( (height \times width \times channels) \)의 shape을 가진 이미지를 N개의 \( (P^2 \times channels) \) shape을 가진 patch로 쪼갠다. 여기서 \( P \)는 patch의 크기이며 모든 입력 이미지의 패치 수는 동일하게 고정된다(BERT에서 시퀀스의 length처럼). 위의 그림에서 하나의 사진이 작은 크기로 쪼개져 sequencial하게 positioning되는 것을 확인할 수 있다.
1-2. Linear projection of Flattened Patches (+Position embedding)

트랜스포머 block에 patch를 넣기 전에 ViT는 먼저 linear projection을 통해 patch를 1-d 벡터로 매핑시키는 방법을 사용하는데, 각 patch를 하나의 벡터로 unroll(flatten)한 다음 embedding size 차원의 벡터로 매핑시킨다(dimensional embedding with size \( D\)).
여기에 positional embedding이라는 것을 concat해 트랜스포머 인코더의 최종 인풋으로 정의한다. 자연어 처리에서의 트랜스포머를 생각해봤을 때, 시퀀스를 한꺼번에 인풋으로 받기 때문에 각 토큰의 위치 정보를 보존해줄 수 있는 수단이 필요했다. 마찬가지로 ViT에서도 patch들의 위치 정보를 유지하기 위해 positional embedding이 patch representation에 추가된다. flatten 되기 전의 patch들은 위치 인덱스와 관련된 일련의 숫자가 있으며(learnable), 트랜스포머 모델은 이 position embedding의 유사도로 이미지 내에서 거리를 인코딩하는 방법을 학습한다.
또 하나 기억해야 할 것은 position embedding을 더해주기 전, class embedding인 [class] vector를 patch set 맨 앞에 추가해주는 스탭이다. 이는 BERT의 [cls] 토큰과 유사하게 트랜스포머 인코더의 출력에서 image representation의 역할을 한다(BERT에서 [cls] 토큰이 무슨 역할을 하는지 모른다면 이 포스트에서 sentence-transformers를 다루며 간단하게 설명해놓았다). [class] 토큰은 pre-trained나 transfer learning에 상관없이 모두 입력값 맨 앞에 부착된다.

1-3. Transformer Encoder Block
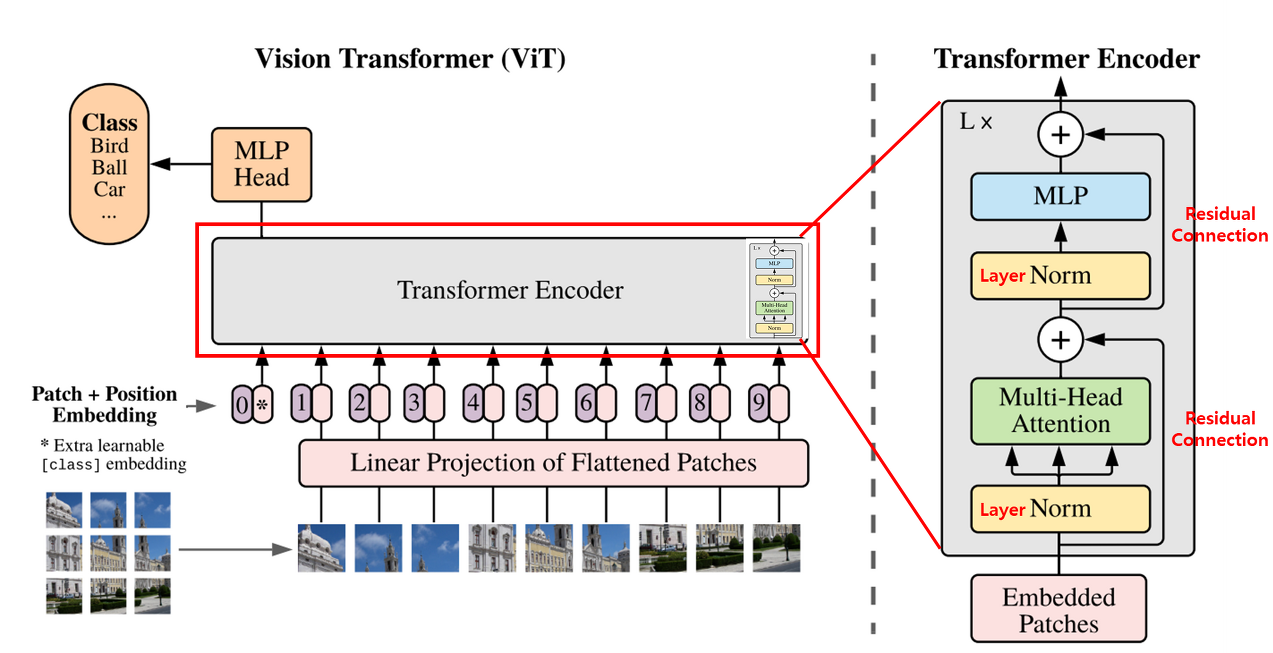
Multi-head self-attention(여기 SAT다.. 그냥 AT아님 주의)과 MLP block이 번갈아 등장하는 형태의 트랜스포머 인코더를 사용한다. LN(layer norm)은 모든 block 앞에 적용되며, Residual connection은 모든 block 뒤에 등장한다.
** trivial한 부분이지만 기존의 자연어 처리 분야에서 처음 소개된 트랜스포머의 인코더("vanilla" transformer)와 살짝 다른 구조를 가지고 있다. Layer normalization이 각 레이어 사이와 끝단에 등장하는 게 아니라 embedding을 입력으로 받고 바로, 그리고 Multi-head attention과 MLP 사이에 등장하는데, 트랜스포머 논문이 발표가 되고 후속 논문들에서 레이어가 깊어질수록 학습이 어려워진다는 단점들을 발견해서 이를 보완하기 위해 변형한 것이라고 한다.
Inductive Bias (내재 편향)
일반적으로 모델이 갖는 일반화의 오류(Generalization Problem)는 불안정하다는 것(Brittle)과 겉으로만 그럴싸 해 보이는 것(Spurious)이 있다. 모델이 주어진 데이터에 대해서 잘 일반화한 것인지, 혹은 주어진 데이터에만 잘 맞게 된 것인지 모르기 때문에 발생하는 문제이다. 이러한 문제를 해결하기 위한 것이 바로 Inductive Bias이다. Inductive Bias란, 주어지지 않은 입력의 출력을 예측하는 것이다. 즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정(Additional Assumptions)이라고 보면 된다.
- 출처 : https://re-code-cord.tistory.com/entry/Inductive-Bias%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
Inductive bias는 새로운 데이터에 대해 좋은 성능을 내기 위해 모델에 사전적으로 주어지는 가정이다. 학습이 성공적으로 끝난 후에, 모델은 훈련 동안에는 보이지 않았던 데이터까지도 정확하게 예측해야 한다. 이럴 때 추가적인 가정이 없이는 불가능한데, 이 target function의 성질에 대해 필요한 가정과 같은 것이 inductive bias이다.
딥러닝의 관점에서, 우리가 흔히 쌓는 레이어의 구성은 일종의 hierarchical processing을 제공한다. 딥러닝 레이어의 종류에 따라 추가적인 relational inductive bias가 부과되며, 가령 CNN 같은 경우 locality라는 inductive bias가 존재한다.
- nearby areas tend to contain stronger patterns (가까운 지역의 pixel들끼리 더욱 관계가 있다)
- relative (rather than absolute) positions are relevant (사물의 종류는 위치에 상관없다)
ViT는 CNN보다 이미지별 inductive bias가 훨씬 적다(트랜스포머 자체가 이미 그렇지만). ViT에서는 MLP 레이어만 국소적(local)이며 self-attention 레이어는 전역적(global)이다. CNN의 또 다른 inductive bias인 two-dimensional neighborhood structure은 ViT에 와서는 매우 적게 사용되는데, 모델의 초기에는 이미지를 patch로 쪼개고 다른 해상도의 이미지에 대한 position embedding을 조정하기 위한 fine-tuning에 사용된다. 그 외에는 초기화 시 position embedding에는 patch의 2차원 위치 정보가 없으며 패치 간의 모든 공간 관계를 처음부터 학습해야 한다. 이것이 가장 위에서 왜 반드시 대규모의 데이터셋으로 fine-tuning해야 하는지에 대한 답이 된다.
1-4. MLP (Multi-Layer Perceptron Head)
출력층에 연결된 완전 연결 MLP head는 클래스 예측에 사용된다. 트랜스포머 인코더를 포함한 main model은 대규모 데이터셋을 통해 pre-trained된 다음 최종 MLP head를 특정 task에 맞게 fine-tuning할 수 있다.
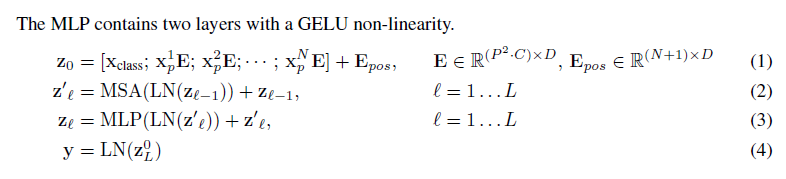
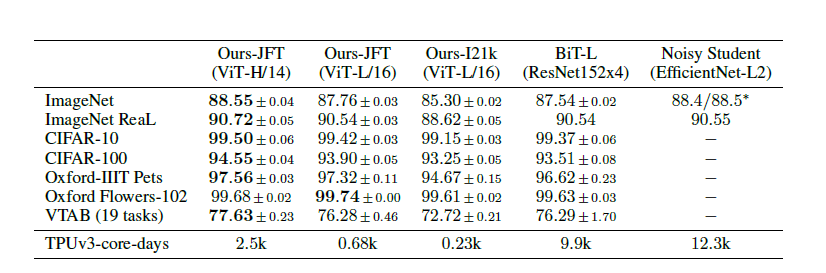
2. Comparison to state-of-art
다음은 ViT를 BiT, VIVI와 같은 SOTA 모델들과 비교하기 위해 VTAB(Visual Task Adaptation Benchmark - general visual representation을 평가하기 위해 설계된 프로토콜)을 통한 transfer learning 성능 평가 지표이다.

자료 출처 : https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/five-reasons-to-embrace-transformer-in-computer-vision/
https://velog.io/@euisuk-chung/Inductive-Bias%EB%9E%80
https://coding-chobo.tistory.com/97



