앞서 살펴보았던 BERTopic이나 KeyBERT 모두 BERT를 이용해 문장 단위의 임베딩을 형성한다(문서 단위의 임베딩도). 내가 아는 것은 단어 단위의 임베딩뿐... 어떻게 문장 단위로, 그리고 문서 단위로 텍스트를 벡터화하는 것일까?
SBERT 논문은 이쪽!
Sentence Transformers(SBERT의 파이썬 라이브러리) documentation: https://www.sbert.net/
SentenceTransformers Documentation — Sentence-Transformers documentation
Performance Our models are evaluated extensively and achieve state-of-the-art performance on various tasks. Further, the code is tuned to provide the highest possible speed. Have a look at Pre-Trained Models for an overview of available models and the resp
www.sbert.net
Unsupervised sentence embedding techniques
SBERT 설명에 앞서 이해해두어야 할 임베딩 방법들을 알아보자.
- N-gram embeddings
[DL] 텍스트 데이터와 언어 모델(Language Model) 포스트에서 이미 언급했지만, n-gram 모델은 주어진 문장에서 n개의 연속된 단어를 텍스트를 나누는 단위로 설정한다(n의 크기에 따라 unigram, bigram 등등으로 나뉨). 그리고 이후 딥러닝 모델을 학습함에 있어 이 phrases를 개별 토큰으로 취급한다. 이는 문장의 길이가 길어질수록 phrase의 크기가 폭발적으로 증가하기 때문에 긴 문장을 학습하는 데 적합하지 않으며, unseen phrases를 처리하는 방법에는 일반화되지 않을 수 밖에 없다.
- Averaging word embeddings
센텐스 단위의 임베딩을 구성하는 매우 직관적인 방법으로는, 문장이 주어지면 문장의 단어에 대응하는 모든 벡터에 대해 벡터 산술(vector arithmetics)을 계산해서 동일한 임베딩 공간에서 하나의 벡터로 요약하는 것이 있다. 일반적으로는 평균 혹은 합계를 사용한다. 가령 위의 n-gram으로 나눈 토큰들의 임베딩을 산술 평균내는 것이다(averaging the embeddings of all the tokens in the sentence).
SBERT (Sentence-BERT)
SBERT는 의미론적으로 의미 있는 문장 임베딩을 도출할 수 있도록 modified된 BERT 네트워크이다. Main task로는 large-scale semantic similarity analysis, 클러스터링 및 semantic search를 통해 정보 검색 등이 있다.
BERT는 다양한 문장 분류와 문장 쌍 회귀 task에서 최첨단의 성능을 자랑하고 있으며, 문장 쌍을 비교하는데 있어 두 문장 전체에 full attention을 하는 cross-encoder를 사용한다. 하지만 cross-encoder의 경우 실제 서비스 환경에서 사용하기 어려울 만큼 속도가 느리다는 단점이 있다(too many possible combinations of paired sentences). 논문에 의하면 4천만 개 이상의 Quora의 기존 질문 중 새로운 질문에 대한 가장 유사한 질문을 찾는데 BERT를 이용한다면, 하나의 질문에 답하는 데 50시간 이상 걸릴 것이라고 한다...ㅎ
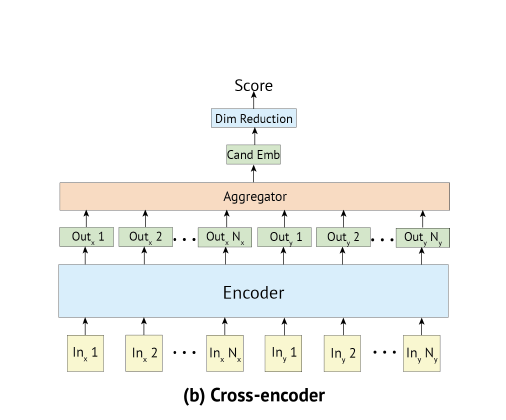
클러스터링과 sematic search를 다루는 일반적인 방법은 의미적으로 유사한 문장이 근접하도록 각 문장을 벡터 공간에 매핑하는 것이다. 개별 문장을 BERT에 넣고 고정 크기의 문장 임베딩을 도출하는 방법이 사용되기 시작으며, BERT의 출력 계층(BERT 임베딩)을 평균내거나 첫 번째 토큰([cls] 토큰)의 출력을 사용하는 등의 접근법이 제시되었다. 하지만 이런 관행은 다소 나쁜 문장 임베딩을 생성한다.
이 문제를 해결하기 위해 고안된 것이 SBERT로, BERT의 문장 임베딩 성능을 우수하게 개선시킨 모델이라고 할 수 있다. SBERT의 이점은 다음과 같이 요약할 수 있다:
- 입력 문장에 대한 고정 크기의 벡터를 도출
- 코사인 유사도 또는 맨하탄/유클리드 거리와 같은 유사성 척도를 계산하는 데 알맞는 임베딩 도출
- 리소스 효율적인 클러스터링 및 semantic similarity search task 수행
1. BERT의 문장 임베딩
BERT로부터 문장 임베딩을 얻는 방법은 총 세 가지가 있다.
- BERT의 [CLS] 토큰의 출력 벡터를 문장 벡터로 간주
- BERT의 모든 단어의 출력 벡터에 대해서 평균 풀링을 수행한 벡터를 문장 벡터로 간주
- BERT의 모든 단어의 출력 벡터에 대해서 맥스 풀링을 수행한 벡터를 문장 벡터로 간주
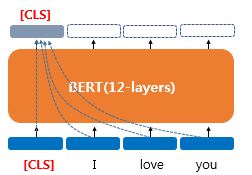
문장에 대한 벡터를 얻는 첫 번째 방법은 [CLS] 토큰의 출력 벡터를 문장 벡터로 간주하는 것이다. BERT는 입력으로 문장을 한꺼번에 넣는다는 것을 상기하자. 따라서 [CLS] 토큰의 출력 벡터는 문장의 문맥을 모두 참고한, 문맥을 반영한 임베딩이 된다(애초에 [CLS] 토큰의 출력 벡터를 BERT 출력층의 입력으로 넣으니 '문장에 대한 총체적인 표현'으로 삼을 수 있음).
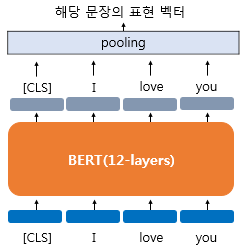
두 번째와 세 번째 방법은 [CLS] 토큰만을 사용하는 것이 아니라 BERT의 모든 출력 벡터들을 평균내거나(MEAN pooling), 각 단어 벡터의 dimension 중 가장 큰 값을 선택(MAX pooling)하는 것이다. 포스트 초반에 설명했던 것처럼 평균값 같은 vector arithmetics를 사용하는 것이다. SBERT에서는 세 가지 방법중 평균 풀링을 default method로 정해놓았다.
SBERT adds a pooling operation to the output of BERT / RoBERTa to derive a fixed sized sentence embedding. We experiment with three pooling strategies: Using the output of the CLS-token, computing the mean of all output vectors (MEANstrategy), and computing a max-over-time of the output vectors (MAX-strategy). The default configuration is MEAN.
- 출처: Sentence-BERT(Sentence Embeddings using Siamese BERT-Networks) 논문
2. Training (fine-tuning)
SBERT는 SNLI 데이터셋과 Multi-Genre NLI 데이터셋으로 학습되었다. SNLI는 57만개의 문장 쌍으로 구성된 모음으로, contradiction, entailment 및 neutral이 라벨링 되어있다. MultiNLI에는 43만 개의 문장 쌍이 포함되어 있으며, 구어 및 문어 텍스트의 다양한 장르를 커버한다.

위의 데이터셋에서 뽑은 두 개의 문장을 A와 B라고 했을 때, A와 B를 각각 BERT의 입력으로 넣고 pooling 계층을 통과시켜 문장 임베딩을 얻는다(default 풀링 방법은 평균). 이를 각각 \(u\)와 \(v\)라 하면, 아래와 같이 두 벡터의 차이를 구한다(\(|u-v|\)).
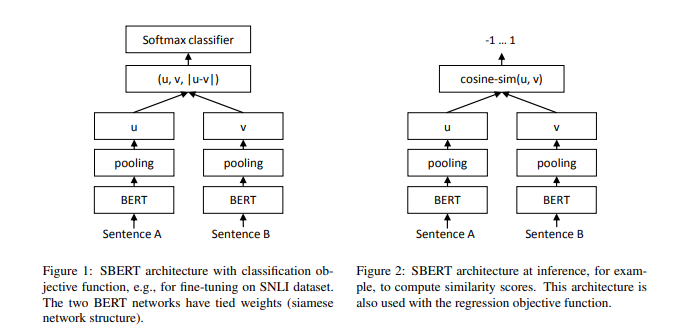
- \( u \) : 문장 A의 임베딩 벡터
- \( v \) : 문장 B의 임베딩 벡터
- \( |u-v| \) : \(u\) 벡터와 \(v\) 벡터의 차이 벡터
Classification Objective Function (그림 왼쪽)
세 벡터를 concat해 출력층으로 보낸다. BERT의 문장 임베딩의 차원이 \(d\)이고 분류하고자 하는 클래스의 개수가 \(k\)개라면, 출력층에서는 (\(3d \times k\))의 크기를 가지는 가중치 행렬 \(W_y\)를 곱한 후 소프트맥스 함수를 통과시키는 과정을 거친다. 즉,
$$ o = softmax(W_y(u, v, |u-v|)) $$
Regression Objective Function (그림 오른쪽)
두 문장 임베딩 \(u\)와 \(v\) 사이의 코사인 유사도가 계산된다. 손실함수로는 MSE(mean squared-error)를 사용한다.



