딥러닝에서 신경망을 공부하다보면 transfer learning과 fine tuning이라는 단어를 심심치않게 접할 수 있다. 둘 사이에는 무슨 차이가 있을까? 사실 필자도 생각없이 혼용하다(ㅋㅋ) 의문점을 해소할 기회가 생겨 정리해두고자 한다.
앤드류 응 교수님의 영상과 StackExchange의 질의응답을 많이 참고했다.
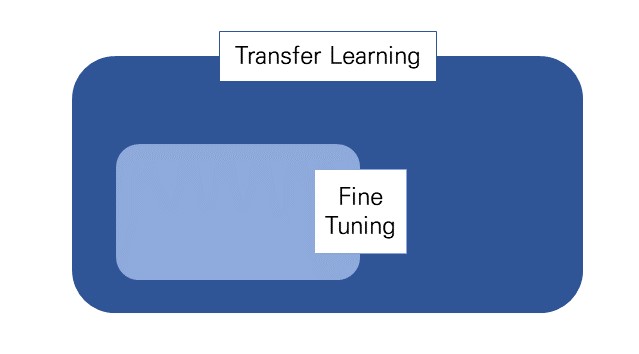
결론부터 이야기하자면 transfer learning의 방법 중 하나가 fine tuning이다.
1. Pre-training (사전훈련)
예시로 상황을 가정해보자. 우리는 아래의 신경망으로 개와 고양이를 분류하려고 한다. 따라서 개와 고양이 이미지와 예측하고자 하는 object의
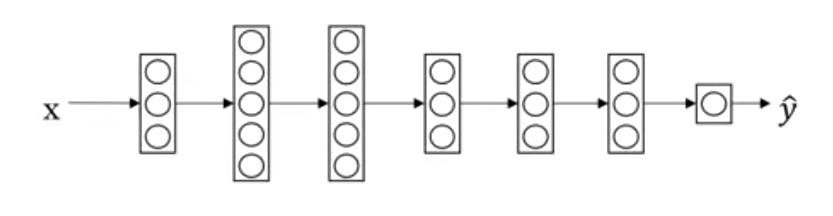
모델이 예측한 값은
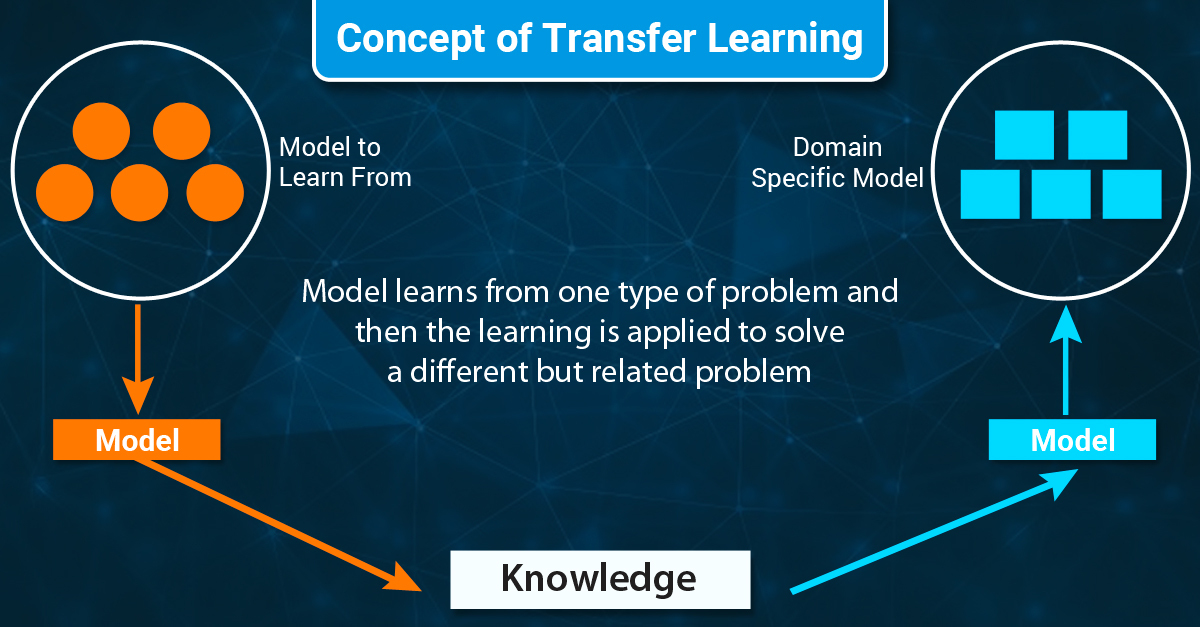
2. Transfer Learning (전이학습)
있다. 위의 pretrained model을 표범, 호랑이 이미지와 각 클래스의 라벨로 구성된 새로운 데이터셋
3. Fine-Tuning (미세조정)
그런데 여기서 더 들어가서, 만약 표범과 호랑이를 구분하는게 아니라 모든 포유류를 분류하고 싶다면? 얻고자 하는 결과값이 다르기 때문에 마지막 output layer를 삭제하고 다른 layer(들)를 붙여서 쓴다. 그리고 모델을 다시 훈련시킨다. 이것을 fine-tuning이라고 한다.
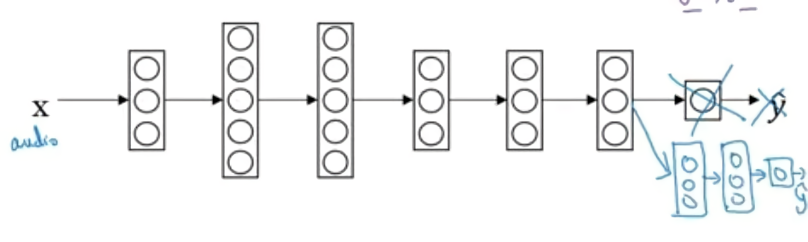
이 예에서는 개와 고양이를 분류하는 모델의 정보를 통해 모든 포유류를 분류하는 데 적용했다. Fine-tuning을 포함한 transfer learning이 유용한 이유는 low level 특성들(선, 점, 곡선같은 부분에 대한 knowledge) 때문인데 윤곽이나 커브를 감지하거나 물체의 일부분을 감지하는 것들이다. 이미 잘 학습된 pre-trained model을 사용하는 것은 이미지가 어떻게 생겼는지에 대한 구조를 이해할 수 있기 때문에 학습 알고리즘이 새로운 모델에서도 더 잘 작동하는 것에 도움이 된다. 따라서 적은 데이터셋으로도 효과를 극대화시킬 수 있다.
fine-tuning을 하는 방법에는 여러 가지가 있다. 위에서 말했던 것처럼 모델의 끝 단을 바꿔끼워서 마지막 layer의 파라미터
Using a pre-trained model in a similar task, usually have great results when we use Fine-tuning. However,
if you do not have enough data in the new dataset or even your hyperparameters are not the best ones, you can get unsatisfactory results. Machine learning always depends on its dataset and network's parameters. And in that case, you should only use the "standard" Transfer Learning (대충 새 데이터셋이 적거나 pretrained-model이 만들고자 하는 새로운 모델의 목적과 비슷하지 않다면 fine-tuning하지 말라는 뜻)
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Topic modeling with BERTopic - 개요 및 알고리즘 (0) | 2022.03.27 |
|---|---|
| [DL] Exploding & Vanishing Gradient 문제와 Residual Connection (0) | 2022.03.17 |
| [DL] 자연어 처리에서의 텍스트 표현 - 단어 임베딩(Word Embedding) (0) | 2022.03.11 |
| [DL] 텍스트 데이터와 언어 모델(Language Model) (0) | 2022.03.10 |
| [DL] Attention 파헤치기 - Seq2Seq부터 Transformer까지 (2) (0) | 2022.03.08 |



