텍스트(text)란 단어의 시퀀스나 문자의 시퀀스로 이해할 수 있다. 시퀀스 처리용 딥러닝 모델은 텍스트를 사용하여 기초적인 자연어 이해 문제를 처리할 수 있는데, 이런 모델은 다음과 같은 어플리케이션에 적합하다.
- 문서 분류(Text Classification)
- 감성 분석(Sentiment Analysis)
- 질문 응답(QA)
컴퓨터는 텍스트를 어떻게 이해할까? 사실 '이해한다'라고 보기보단 문자 언어에 대한 통계적 구조를 만들어 문제를 해결한다고 볼 수 있다. [DL] 합성곱 신경망 파헤치기 포스트의 배경으로 등장했던 컴퓨터 비전이 이미지의 픽셀에 적용한 패턴 인식인 것처럼, 언어 모델은 단어, 문장, 문단에 적용한 패턴 인식인 것이다.
언어 모델
딥러닝에서 시퀀스 데이터를 생성하는 일반적인 방법은 이전 토큰을 입력으로 사용해서 시퀀스의 다음 1개 혹은 몇 개의 토큰을 예측하는 것이다.
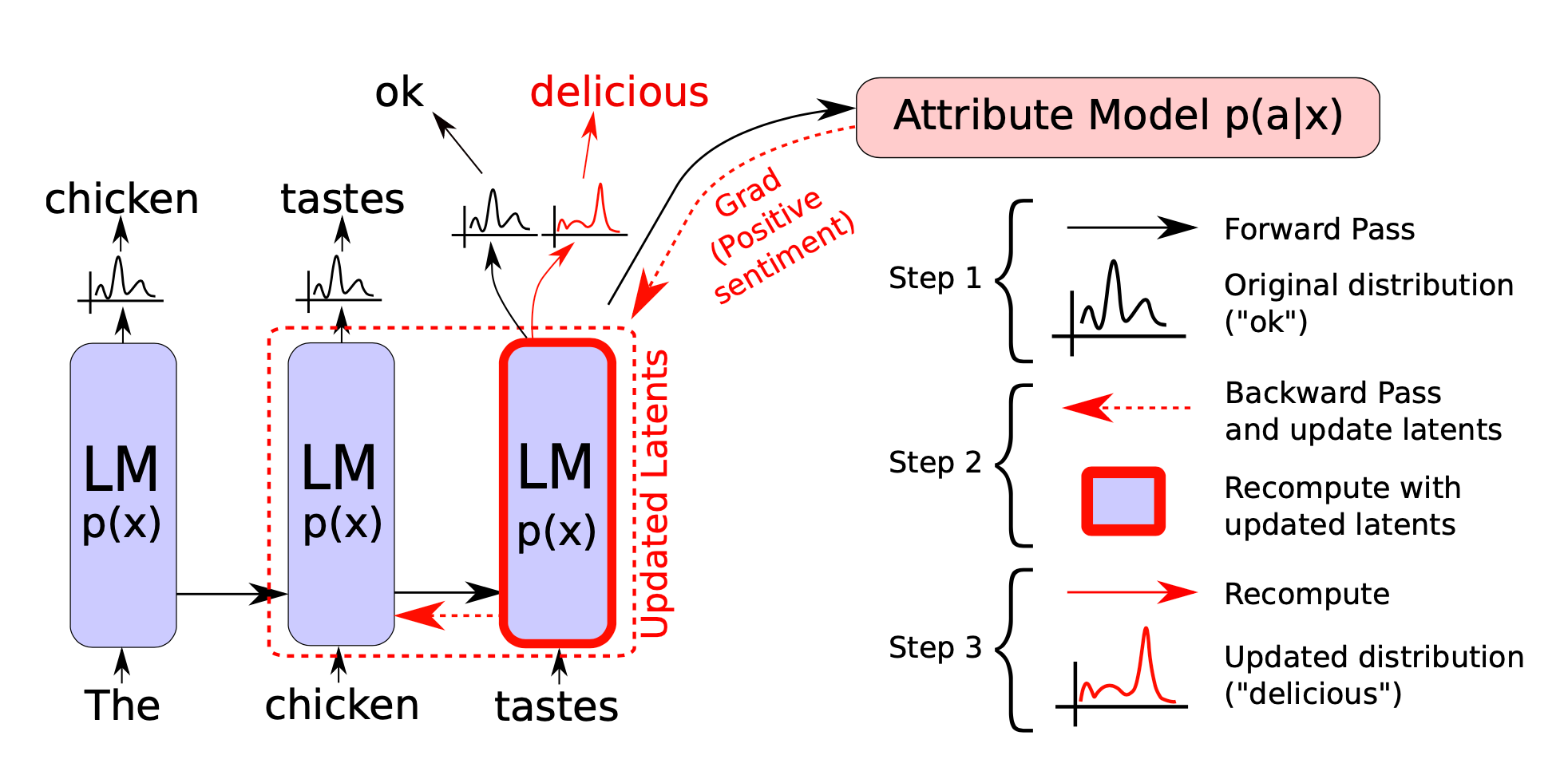
이전 토큰들이 주어졌을 때 다음 토큰의 확률을 모델링할 수 있는 네트워크를 언어 모델(language model)이라고 부른다. 다시 말해, 언어 모델은 단어의 순서에 대한 확률 분포이다. 위에서 말한 '통계적 구조'를 만들어 확률값을 할당한다고도 할 수 있다. 문장의 구조가 완벽할 수록, 즉 "아, 이건 말이 된다"고 판단될 수록 더 높은 확률을 부여한다.
언어 모델은 크게 통계적 언어모델, n-gram 언어모델과 딥러닝 기반 언어모델로 나눌 수 있다.
1. 통계적 언어모델(SLM; Statistical Language Model)
조건부 확률을 이용하여 현재까지의 문자 시퀀스 바로 뒤에 나올 가장 높은 확률의 단어를 찾는 모델이다. 특정 영역에서의 말뭉치를 기반으로 단어 set을 만들어두고 그 안에서 확률을 계산해 단어를 찾는 방식이기 때문에 context-dependent한 성격을 가진다. 특정 domain에 대한 dependency가 크다는 뜻인데, 통계적 언어모델은 학습 데이터에 매우 민감하다.
초창기에 나온 것이 유니그램 모델(unigram model)이다. 각 단어가 서로 독립이라고 가정할 때, n개의 단어가 동시에 나타날 확률은 다음과 같다.
$$ P(w_1, w_2, ..., w_n) = \prod _{i=1}^n P(w_i) $$
유니그램 모델은 다음과 같은 테이블로 구성된다. 학습말뭉치에 등장한 각 단어 빈도를 세어서 전체 단어수로 나누어준 것이다.

텍스트마이닝 학습말뭉치로 학습한, 위와 같은 유니그램 모델 \( θ \)가 주어진 상황에서 ‘world’와 ‘we’, ‘share’이라는 세 개 단어로 구성된 첫번째 문서 D의 출현확률을 구해보자.
\begin{align*} P(D|\theta) & = P(world\: we\: share|\theta) \\
& = P(world|\theta)\times P(we|\theta)\times P(share|\theta) \\
& = 0.2\times 0.05\times 0.3 \\
& = 0.003 \end{align*}
희소 문제(sparsity problem)
통계적 언어모델의 단점은 학습말뭉치에 존재하지 않는 단어의 경우 그 확률이 0이 된다는 것이다. 이미 언급했던 것처럼 학습말뭉치에 의존적이기 때문에 범용적인 모델을 구축하기가 어렵다. 따라서 information retrieval context에서는 확률이 0이 되는 경우를 피하기 위해 종종 단일그램 언어 모델을 smoothen한다. 공통 접근법은 전체 수집에 대한 최대 우도 모델을 생성하고 각 문서에 대한 최대 우도 모델로 선형 보간하여 모델을 smoothen하는 것이다(위키백과의 선형 보간법 참고).
2. n-gram 모델
SLM의 희소 문제를 보완하기 위해 고안되었다. 주어진 문장 전체가 아닌 바로 양 옆의 n개의 단어를 보고 다음 단어를 예측하는 방법이다. n-gram은 텍스트를 나누는 단위이기 때문에 n의 크기에 따라 종류가 나뉜다.
예를 들어 두 문자열 "it's bad, not good at all"과 "it's good, not bad at all"이 있다고 하자. 단어 'not'을 기준으로 의미가 완전히 반대가 된다. 이는 문맥(context)의 중요성을 잘 보여주는 예시라고 할 수 있는데, 문맥도 반드시 고려해야 의미를 유지한 채로 변환할 수 있는 것이다. n-gram은 이를 반영하기 위해 토큰 하나의 횟수만 고려하지 않고 옆에 있는 두세 개의 토큰을 함께 고려한다. 다음과 같은 종류들이 있으며 일반적으로 연속된 토큰을 n-gram이라고 한다.
- unigrams : n이 1인 경우
- bigrams : n이 2인 경우
- trigrams : n이 3인 경우

3. 순환신경망 계열 언어 모델
우리는 이미 [DL] 순환 신경망 - RNN, LSTM, GRU 파헤치기 포스트를 통해 순환신경망 계열 딥러닝 모델이 무엇인지 알고 있다. 초기 단계인 RNN은 이전 상태값과 현재 입력을 조합하여 새로운 상태값을 계산해 내는 신경망이다. 즉, 현재 상태값에 다음 입력을 조합하면 그 다음 상태값을 계산하게 된다. 이 때문에 입력이 순서대로 들어오면 그 길이가 정해져 있지 않은 데이터를 고정된 크기의 가중치로 처리해낼 수 있다. 순환신경망 계열은 고전적인 RNN과, 입력 데이터의 길이가 길어질수록 학습이 어려워지는 문제가 있어 이를 개선하기 위해 등장한 LSTM, LSTM의 복잡한 연산을 단순화시킨 GRU가 있다.
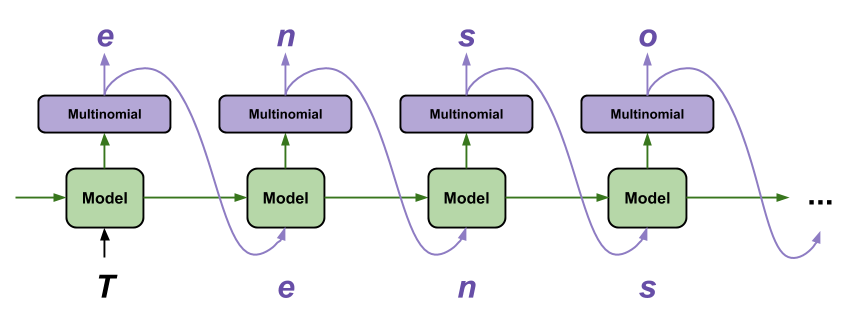
텍스트 말뭉치(corpus)에서 n개의 글자로 이루어진 문자열을 추출하여 주입하고 \( n+1 \)번째 글자를 예측하도록 훈련한다. 모델의 출력은 출력 가능한 모든 글자에 해당하는 소프트맥스 값이다(다음 글자의 확률 분포).
'AI > Deep Learning' 카테고리의 다른 글
| [DL] Transfer Learning vs Fine-tuning, 그리고 Pre-training (0) | 2022.03.17 |
|---|---|
| [DL] 자연어 처리에서의 텍스트 표현 - 단어 임베딩(Word Embedding) (0) | 2022.03.11 |
| [DL] Attention 파헤치기 - Seq2Seq부터 Transformer까지 (2) (0) | 2022.03.08 |
| [DL] Attention 파헤치기 - Seq2Seq부터 Transformer까지 (1) (0) | 2021.11.10 |
| [DL] 순환 신경망 - RNN, LSTM, GRU 파헤치기 (0) | 2021.10.25 |



