아래 포스트를 통해 정규화와 표준화가 무엇인지 살펴보았으니, scikit-learn에서의 feature scaling 방법들을 소개해보려 한다.
[통계] 정규화와 표준화, Normalization vs Standardization
ML을 공부하는 사람이라면 feature scaling이 얼마나 중요한 지 알것이다. scikit-learn에는 많은 스케일링 메서드들이 모듈화 되어있는데, 기본적으로 정규화와 표준화가 무엇인지 이해해야 과제를 수
heeya-stupidbutstudying.tistory.com
mglearn 라이브러리는 랜덤한 데이터셋이나 머신러닝 적용 결과를 보기좋게 표현하기 위한 함수들을 생성해준다.
mglearn.plots.plot_scaling을 통해 scikit-learn이 제공하는 스케일링 방법들을 시각화해서 볼 수 있다.
import mglearn
mglearn.plots.plot_scaling()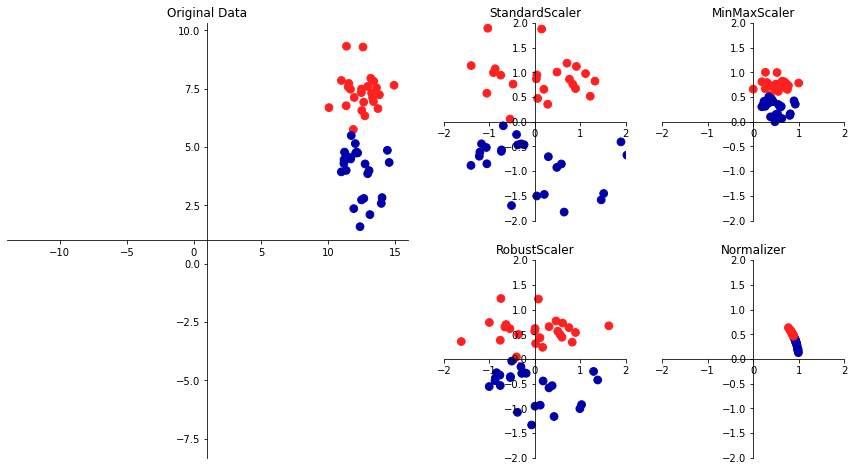
1. StandardScaler
각 피처의 평균을 0, 분산을 1로 변경하여 모든 피처가 같은 크기를 가지게 한다. StandardScaler를 구하는 공식은
$$ z = \frac{x-\mu}{\sigma} $$
이며 \( \mu \)는 평균, \( \sigma \)는 표준편차이다. \( z \)를 표준점수, 혹은 Z-점수(Z-score)라고도 한다. 이 방법은 피처의 최솟값이나 최댓값 크기를 제한하지 않는다.
2. RobustScaler
피처들이 같은 스케일을 갖게 된다는 통계적 측면에서는 StandardScaler와 비슷하지만, 평균과 분산 대신 중간값(median)과 사분위값(quartile)을 사용한다. 중간값은 x보다 작은 수가 절반이고 x보다 큰 수가 절반인 x값을 말한다. 사분위값이란 데이터 표본을 4개의 동일한 부분으로 나눈 값이다.

따라서 RobustScaler는 이상치(outlier)의 영향을 받지 않는다. 전체 데이터와 아주 동떨어진 데이터 포인트(가령 측정 에러)를 이상치라고 하는데, 이 값 때문에 다른 feature scaling 기법에서는 문제가 발생할 수 있다.
3. MinMaxScaler
모든 피처가 정확하게 0과 1 사이에 위치하도록 데이터를 재조정한다. Min-Max Scaling 정규화 공식을 이용한다.
$$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$
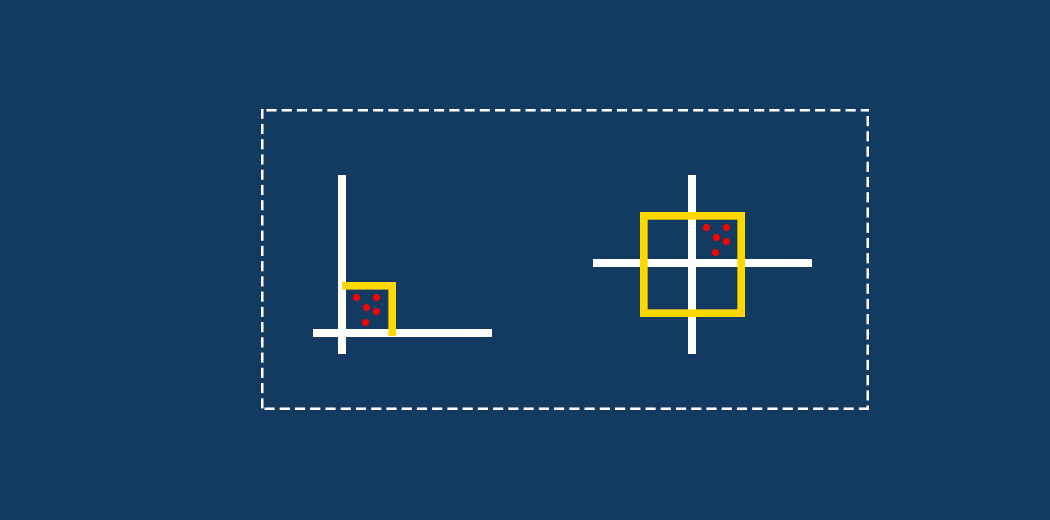
4. Normalizer
피처 벡터의 유클리디안 거리(Euclidean distance)가 1이 되도록 데이터를 재조정한다(맨 위의 mglearn 그래프를 보면 이해가 쉽다). KNN, K-means, SVM과 같이 피처의 범위에 영향을 많이 받는 distance-based algorithm을 이용할 때 전처리 방식으로 자주 등장한다. 학생 A,B,C,D,E의 성적과 미래 임금을 가지고 예를 들어보자. 임금의 단위는 '000 Rupee이다.
data = {'CGPA': [3.0, 3.0, 4.0, 4.1, 4.2],
'Salary(000)': [60, 40, 40, 50, 52]}
df = pd.DataFrame(data, index=['A', 'B', 'C', 'D', 'E'])
df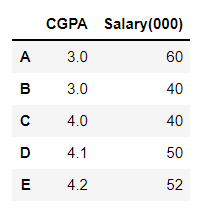
CGPA와 임금은 다른 척도를 가진 피처이다. 이 데이터들을 그냥 사용하면 크기가 큰 임금 피처에 더 큰 가중치가 부여될 가능성이 있다. 우리는 기계 학습 알고리즘이 하나의 특성에 치우치지 않기를 바란다. 따라서 기계 학습 알고리즘을 사용하기 전에 데이터를 스케일링하여 모든 피처 결과에 동일하게 기여하도록 한다.
from sklearn.preprocessing import Normalizer
X = df.values
normalizer = Normalizer()
X_scaled = normalizer.fit_transform(X)
new_df = pd.DataFrame(X_scaled, index=['A', 'B', 'C', 'D', 'E'], columns=['CGPA', 'Salary(000)'])
new_df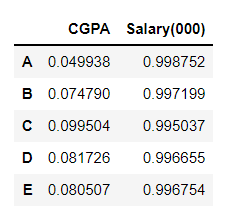
필자는 이 Normalizer가 MinMaxScaler랑 어떤 점에서 다른지 고민을 좀 했는데, scikit-learn 공식 도큐멘트에서 설명하기로는 이러하다.
Normalize samples individually to unit norm.
Each sample (i.e. each row of the data matrix) with at least one non zero component is rescaled independently of other samples so that its norm (l1, l2 or inf) equals one.
This transformer is able to work both with dense numpy arrays and scipy.sparse matrix (use CSR format if you want to avoid the burden of a copy / conversion).
Scaling inputs to unit norms is a common operation for text classification or clustering for instance. For instance the dot product of two l2-normalized TF-IDF vectors is the cosine similarity of the vectors and is the base similarity metric for the Vector Space Model commonly used by the Information Retrieval community.
MinMaxScaler는 공식을 봐도 알 수 있지만, 최솟값과 최댓값의 범위를 기준으로 그 비율만큼 데이터 포인트가 재조정된다. 즉 각 column의 통계치가 계산에 반영된다(이것은 StandardScaler, RobustScaler도 마찬가지). 하지만 Normalizer을 사용할 경우 각 표본(데이터 행렬의 각 row)은 다른 표본과 독립적으로 재조정된다. default norm으로는 L2 Distance가 이용된다.
'AI > Statistics' 카테고리의 다른 글
| [통계] 4가지 측정척도, Pearson correlation & Spearman rank correlation (0) | 2021.09.21 |
|---|---|
| [통계] 회귀모형의 진단 (0) | 2021.09.14 |
| [통계] 정규화(Normalization) vs 표준화(Standardization) (0) | 2021.09.14 |
| [통계] F-분포와 분산 분석 ANOVA (0) | 2021.09.14 |
| [통계] 여러가지 분포 - 정규분포, 이항분포, t-분포, 카이제곱-분포 (0) | 2021.09.14 |



