이진탐색트리를 구현해보자.
이진탐색트리는 이진트리 기반의 탐색을 위한 자료구조이다. 효율적인 탐색을 위해 inorder traversal(중위순회) 방법을 씀. 이러면 자료가 오름차순으로 정렬되어서 시간복잡도를 줄일 수 있다고 한다.
| 최선의 경우 | 최악의 경우 |
| 이진트리가 균형적으로 생성되어 있는 경우 : h=log(n) | 경사 이진트리(일렬로 쭉 늘어선 트리) : h=n |
| 시간복잡도: O(log(n)) | 시간복잡도: O(n) |
[C]트리와 이진트리 포스트에서 이진트리의 성질 부분을 다시 복습하자.
n개의 노드를 가진 이진트리의 높이는 최대 n이거나 최소 [log(n+1)]이 된다.
왜 log(n+1)에서 log(n)이 됐는지는 모르겠지만..? 아마 Big-O 기법이 뭉뚱그려서 최고순위 차수만 고려해서(?) 그런가보다.. 아무튼 시간복잡도를 줄이는 것이 중요하기 때문에 AVL 트리 같이 트리를 균형지게 만드는 기법이 소개된다

- 탐색연산: 키값과 루트를 비교한다. 비교한 결과가 같으면 탐색이 성공적으로 끝난다. 키값이 루트보다 작으면 왼쪽 자식을 기준으로 다시 탐색하고, 키값이 루트보다 크면 오른쪽 자식을 기준으로 다시 탐색한다.
- 삽입연산: 탐색을 먼저 수행하고, 탐색에 실패한 위치(즉, NULL일 때)에 새로운 노드를 삽입하면 된다
- BST는 삭제연산이 좀 복잡하다.
- 삭제하려는 노드가 단말노드일 경우
- 삭제하려는 노드가 하나의 서브트리만 가지고 있는 경우
- 삭제하려는 노드가 두개의 서브트리를 가지고 있는 경우
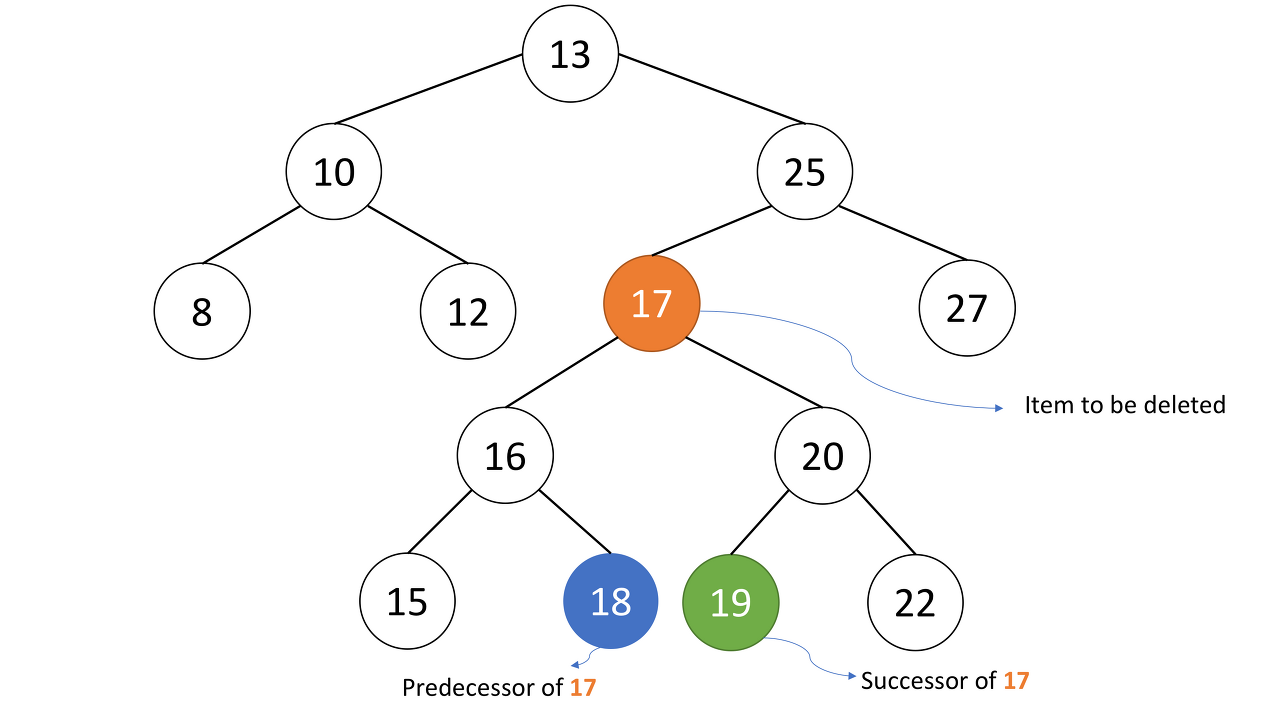
위의 그림에서 12번 노드를 삭제한다고 가정해보자. 그냥 부모노드인 10번 노드의 링크필드를 NULL로 만들면 연결이 끊어진다. (1)의 경우는 이렇게 하고 free하면 된다. 그림에는 없지만 자식노드가 하나인 경우((2)에 해당) 해당 노드의 부모노드의 링크필드를 자식노드를 가리키게 하면 된다. (3)의 경우는 그림으로 설명하겠다.
우리는 17번 노드를 없애고 싶다. 그냥 없애고 16과 20을 연결해버리면 이중트리가 아니게 된다. 이때 17과 가장 가까운 값을 올려야하는데, 18번과 19번 노드가 이에 해당된다. 잘 보면 루트를 기준으로 왼쪽 서브트리의 가장 오른쪽 값과, 오른쪽 서브트리의 가장 왼쪽 값이 제일 비슷하다는 것을 알 수 있다. 가령 그림의 전체 트리에서 루트노드인 13을 없애고자 하면, 왼쪽 서브트리의 가장 큰값인 12번과 오른쪽 서브트리의 가장 작은값인 15가 이에 해당한다는 것이다.
이제 중위순회를 가정해보자. [왼->루트노드->오] 순으로 탐색하면 다음과 같은 순서가 나온다.
8 - 10 - 12 - 13 - 15 - 16 - 18 - 17 - 19 - 20 - 22 - 25 - 27
17번 노드의 위치를 확인해보면 양 옆으로 18과 19가 있다는 것을 알 수 있다. 즉, 이들 노드는 BST를 중위순회하였을 경우, 각각 선행노드(predecessor)과 후속노드(successor)에 해당한다. 둘 중에서는 어떤 것을 선택해도 상관이 없다. 그냥 해당 노드를 복사해서 루트노드에 배정하고, 삭제해버리면 된다.
이 과정을 이해하면 왜 BST에서 중위순회로 탐색을 하면 시간복잡도가 줄어드는지 알 수 있다!
삭제연산만 따로 만들어보았다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
/*
일단 삭제하기 전에, 단말노드를 찾는 함수 find_leaf를 정의한다.
그래야 3번의 경우 삭제하기 쉬움!
*/
Node* find_leaf(Node* root) {
Node* current = root;
while (current->left != NULL)
current = current->left;
return current;
}
Node* delete(Node* root, int key) {
if (root == NULL) return root;
if (key < root->key) root->left = delete(root->left, key);
else if (key > root->key) root->right = delete(root->right, key);
//여기까지는 key와 루트의 데이터가 다른 경우이다. 밑에서부터가 '삭제할 노드를 찾았을 때 어떻게 하느냐'의 방법론
else {
if (root->left == NULL) {
Node* temp = root->right;
free(root);
return temp;
}
else if (root->right == NULL) {
Node* temp = root->left;
free(root);
return temp;
}
else { //여기가 3번의 경우이다! temp라는 포인터변수에 단말노드를 찾아서 복사해준다.
Node* temp = find_leaf(root->right); //중위순회 시 후속노드를 복사한다.
root->key = temp->key; //복사한 것을 루트노드에 붙여넣기
root->right = delete(root->right, temp->key); //후속노드 삭제
}
return root;
}
}
|
cs |
단말노드를 찾는 함수를 먼저 정의해줘야 한다. 필자는 3번의 삭제연산을 수행할 때 루트노드의 오른쪽 서브트리에서 가장 왼쪽값을 찾아서 루트노드로 재배정할 것이기 때문에 find_leaf함수를 current->left로 계속 이동하게 만드는 재귀함수를 사용했다. delete함수에서 3번 연산을 구현한 부분을 보면, root->right를 find_leaf의 인자로 넘겨준 것을 볼 수 있다.
책을 참고해서 짜봤는데... 의문점이 있다. delete함수의 else문 안의 조건들에 대한 의문이다. 왜 단말노드일 경우는 생각 안하는 것 같지...?? root->left == NULL 일 때랑 root->right == NULL 일때는 어느쪽이든 자식노드가 하나는 있다는 가정이잖아... root->left && root->right == NULL 인 조건식이 하나 더 나와야되는 거 아닌가???
놀랍게도 이게 없어도 아무문제 없이 돌아간다. 납득은 안가지만.. ㅎ 아무튼 가장 까다로운 삭제연산을 보았으니 프로그램을 하나 짜보도록 한다.
주제: 단어장(영단어&한국어뜻) 만들기
- 전부 출력했을 때 영단어 기준 오름차순으로 구현되어야 한다
- 영단어는 대문자 소문자 구별을 하지 않는다 ex. ZeBra와 zebra는 같은 단어로 인식
- 탐색은 영단어, 한국어뜻 둘 다 가능하게 해야 한다
첫 번째 조건을 보면 알겠지만 전체 출력하는 함수는 중위순회로 탐색해야 한다. 그리고 대소문자를 구별하지 않으려고 영단어는 모두 대문자로 만들어서 비교했다. 이것 때문에 한 층 짜증나게 코드를 짰다. 그냥 strcmp쓸 수 있었는데... 덕분에 영단어 비교 따로, 한국어뜻 비교 따로 해야 하잖아?ㅡㅡ
<소스코드>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
|
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
#include <string.h>
#include <ctype.h>
#define MAX_WORD 20
#define MAX_MEANING 20
typedef struct {
char word[MAX_WORD];
char meaning[MAX_MEANING];
}element;
typedef struct TreeNode {
element key;
struct TreeNode* left, * right;
}Node;
int compare_word(element a, element b) { //영단어 전부 대문자로 비교
unsigned int size1 = strlen(a.word); unsigned int size2 = strlen(b.word);
char upper_a[MAX_WORD] = { 0 }; char upper_b[MAX_WORD] = { 0 };
for (unsigned int i = 0; i < size1; i++) upper_a[i] = toupper(a.word[i]);
for (unsigned int j = 0; j < size2; j++) upper_b[j] = toupper(b.word[j]);
return strcmp(upper_a, upper_b);
}
int compare_meaning(element a, element b) {
return strcmp(a.meaning, b.meaning);
}
Node* new_node(element value) {
Node* node = (Node*)malloc(sizeof(Node));
node->key = value;
node->left = NULL;
node->right = NULL;
return node;
}
Node* search_word(Node* root, element key) {
Node* temp1 = root;
while (temp1 != NULL) {
if (compare_word(key, temp1->key) == 0) return temp1;
else if (compare_word(key, temp1->key) < 0) temp1 = temp1->left;
else temp1 = temp1->right;
}
return temp1;
}
Node* search_meaning(Node* root, element key) {
Node* temp2 = root;
while (temp2 != NULL) {
if (compare_meaning(key, temp2->key) == 0) return temp2;
else if (compare_meaning(key, temp2->key) < 0) temp2 = temp2->left;
else temp2 = temp2->right;
}
return temp2;
}
//영단어 한국어뜻 따로따로 비교하게 해서 내용은 똑같은데 이름만 다른 탐색용 함수 두개 만듬! 쓰레기!
Node* find_leaf(Node* node) {
Node* current = node;
while (current->left != NULL)
current = current->left;
return current;
}
Node* insert(Node* node, element key) {
if (node == NULL) return new_node(key);
else {
if (compare_word(key, node->key) < 0) {
node->left = insert(node->left, key);
}
else if (compare_word(key, node->key) > 0) {
node->right = insert(node->right, key);
}
return node;
}
}
Node* delete(Node* root, element key) {
if (root == NULL) return root;
else {
if (compare_word(key, root->key) < 0) {
root->left = delete(root->left, key);
}
else if (compare_word(key, root->key) > 0) {
root->right = delete(root->right, key);
}
else {
if (root->left == NULL) {
Node* temp = root->right;
free(root);
return temp;
}
else if (root->right == NULL) {
Node* temp = root->left;
free(root);
return temp;
}
else {
Node* temp = find_leaf(root->right);
root->key = temp->key;
root->right = delete(root->right, temp->key);
}
}
return root;
}
}
void print_all(Node* p) {
if (p != NULL) {
print_all(p->left);
printf(" %s : %s\n", p->key.word, p->key.meaning);
print_all(p->right);
}
}
int main(void) {
int sel; int num = 0;
element data;
Node* root = NULL;
Node* searching1, * searching2;
while (1) {
do {
printf("[1.input 2.delete 3.search(word) 4.search(meaning) 5.print 0.Exit]: ");
scanf("%d", &sel);
} while (sel < 0 || sel > 5);
if (sel == 1) {
printf(" Word: ");
scanf("%s", data.word);
getchar();
searching1 = search_word(root, data);
if (searching1 != NULL) printf(" This word already exists !!\n");
else {
printf(" Meaning: ");
scanf("%s", data.meaning);
getchar();
root = insert(root, data);
}
}
else if (sel == 2) {
printf(" Search(Word): ");
scanf("%s", data.word);
getchar();
searching1 = search_word(root, data);
if (searching1 != NULL) {
root = delete(root, data);
printf(" This word is deleted successfully from My Dictionary.\n");
}
else printf(" This word is not found !!\n");
}
else if (sel == 3) {
printf(" Search(Word): ");
scanf("%s", data.word);
getchar();
searching1 = search_word(root, data);
if (searching1 != NULL) {
printf(" << Search result >>\n");
printf(" %s : %s\n", searching1->key.word, searching1->key.meaning);
}
else printf(" This word is not found!!\n");
}
else if (sel == 4) {
printf(" Search(meaning): ");
scanf("%s", data.meaning);
getchar();
searching2 = search_meaning(root, data);
if (searching2 != NULL) {
printf(" << Search result >>\n");
printf(" %s : %s\n", searching2->key.word, searching2->key.meaning);
}
else printf(" This word is not found !!\n");
}
else if (sel == 5) {
printf(" << My Dictionary >>\n");
print_all(root);
}
else break;
}
return 0;
}
|
cs |
<결과 창>
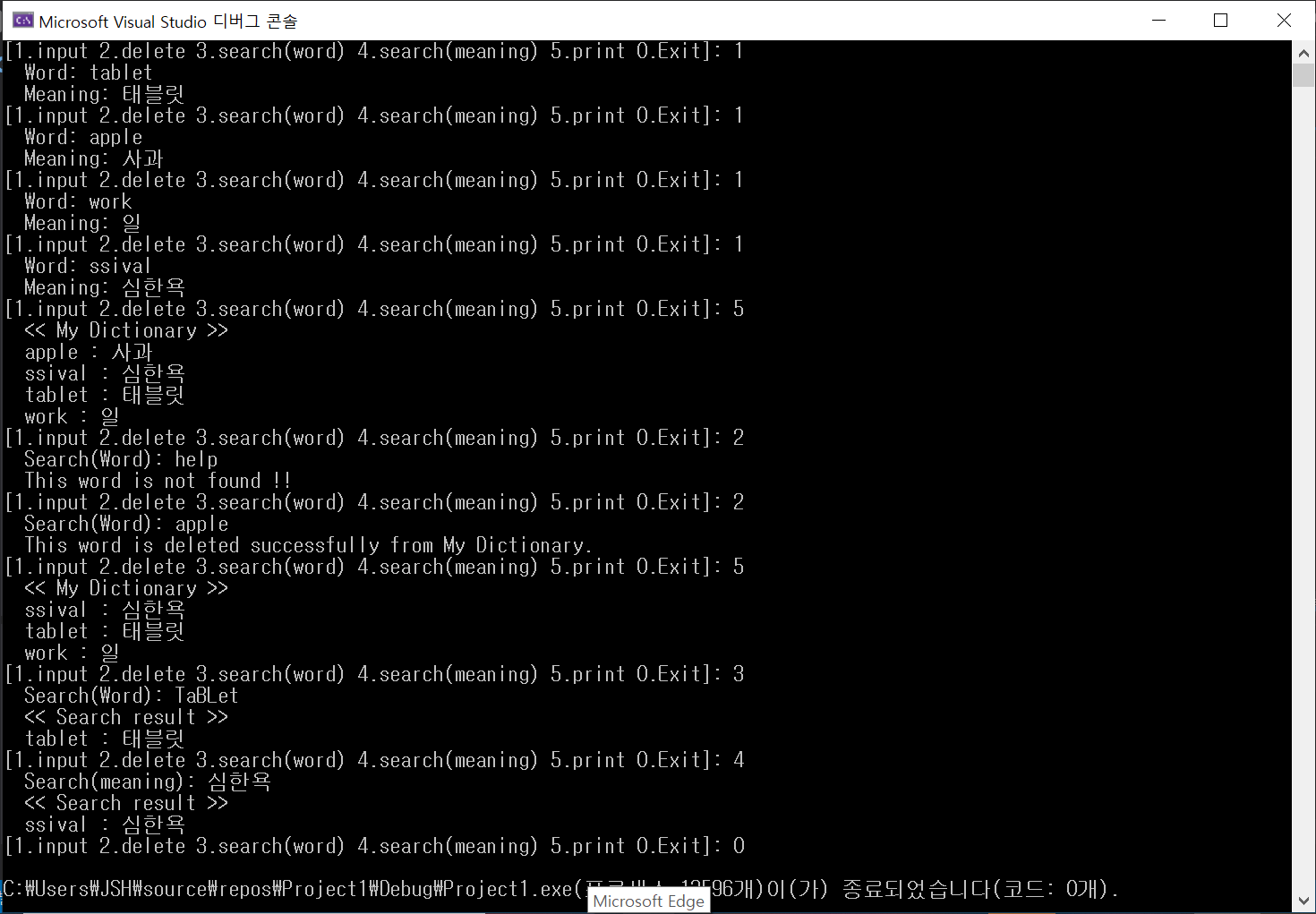
하하 교수님의 모범답안을 봤는데 시작부터 다르네~ 그래도 잘 돌아간다는 것에 의의가 있다.!
더 효율적으로 코딩하는 방법을 익혀야겠다.
'coding > Data Structure(C)' 카테고리의 다른 글
| [C] 힙과 우선순위 큐 (0) | 2020.12.13 |
|---|---|
| [C] AVL트리 (0) | 2020.12.13 |
| [C] 이진트리의 순회 (0) | 2020.12.12 |
| [C] 트리와 이진트리 (0) | 2020.12.12 |
| [C] 큐와 연결리스트 (0) | 2020.12.12 |



