범주형 변수 (categorical variable)
캐글에서 주워온 데이터를 사용해 변주형 변수를 처리하는 방법과 scikit-learn 예시를 정리해보려 한다. 데이터셋에 대한 자세한 설명은 링크를 통해 볼 수 있다.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
df = pd.read_csv('gender_personal_preferences.csv')
df
이 데이터셋을 이용해 어떤 사람의 성별이 여성(F)일지 남성(M)일지 예측하려고 한다. 데이터셋에는 사람이 선호하는 색깔, 음악 장르, 술, 음료 이렇게 4가지의 특성이 있다. 이 작업은 성별(Gender)이 F와 M이라는 두 클래스를 가진 분류 문제로 볼 수 있다. 대신 익숙하게 다뤘던 연속형 특성이 아닌, 범주형 특성들로만 이루어져 있다. 이런 특성들은 어떤 범위가 아닌 고정된 목록 중 하나를 값으로 가지며, 정량적이 아니고 정성적인 속성이다.
범주형 변수를 그냥 Classifier에 넣으면 에러가 뜨면서 작동하지 않는다. 따라서 분류기나 예측기에 넣기 전에 숫자로 인코딩을 해줘야 한다. 보통 두 가지 방법을 사용한다.
1. 라벨 인코딩 (Label Encoding)
Scikit-learn - LabelEncoder()
각 변수별 속성에 알파벳 순서에 따라 unique한 정수가 할당된다. 속성값을 그냥 정수로 바꿔주는 것이기 때문에 dataframe 자체의 크기가 커지거나 줄어들지 않는다. shape도 유지된다. 밑에 나올 one-hot encoding이 변수 안의 속성값의 종류만큼 열을 추가해서 늘린다는 걸 감안하면 비교적 dense하다.
위의 데이터를 가지고 이어서 해보겠다. target 변수인 Gender를 따로 떼어주고, train/test set으로 나눠준다. 그 다음 train셋에 fit_transform 한 뒤 test셋을 transform한다.
X = df.drop('Gender', axis=1)
y = df['Gender']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=123)
print("Size of X_train: {}".format(X_train.shape))
# Size of X_train: (52, 4)
print("Size of X_test: {}".format(X_test.shape))
# Size of X_test: (14, 4)
# 주의: LabelEncoder는 dataframe의 열마다 접근해야 한다.
# 아니면 해당 에러 발생 "ValueError: y should be a 1d array, got an array of shape (52, 4) instead."
for col in list(X_train.columns):
le = LabelEncoder()
X_train[col] = le.fit_transform(X_train[col])
X_test[col] = le.transform(X_test[col])
X_train.head()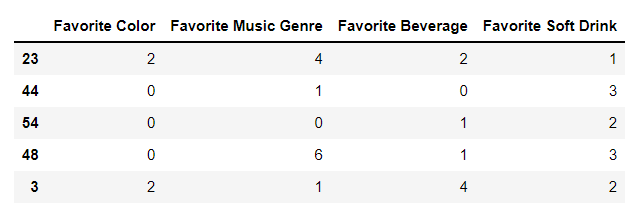
여기서 주의할 것이 있다. 첫 번째는 scikit-learn의 LabelEncoder는 1차원 array만 입력받는다는 것이다. 즉, dataframe을 통째로 넣으면 에러 뜸. 각 column 마다 LabelEncoder 객체를 새로 불러와 인코딩하는 것이 정석이다. 두 번째는 웬만해서는 쓰면 안된다는 것이다! 스텍오버플로에 관련된 질의응답이 있어서 가져와봤다. 순서가 없는(독립적인) 속성값들을 연속형 수치로 바꾸게 되면 학습 과정에서 의도적이지 않게 가중치에 차이를 두게 된다. 예를 들어, 현재 dataframe에 소득(Income)이라는 특성이 추가된다고 생각해보자. 보통 백만원 단위로 월급을 받기 때문에 300, 200 이런식의 속성값들을 가질텐데, 현재 인코딩 된 정수들은 모두 한자리수이다. 소득이 다른 특성들에 비해 거의 100배 가까이 높은 값을 갖기 때문에 결과에 더 큰 영향을 미친다. 그렇다고 해서 소득이 Favorite Color라는 특성보다 더 중요하다고 단정지을 수 있을까? 아닐 것이다.
그래서 변수의 cardinality가 높아도 라벨 인코딩 방식을 쓰기 보단 범주형 변수를 처리할 수 있는 분류기를 쓰곤 한다. CatBoost, lightGBM의 경우 인코딩을 하지도 않은 범주형 변수를 그냥 넣어줘도 처리할 수 있게끔 설계되어 있다. 오오...
2. 원-핫 인코딩 (One-Hot encoding)
라벨 인코딩 방식보다 더 자주 쓰는 것이 원-핫 인코딩 방식이다. 범주형 변수를 0 또는 1 값을 가진 하나 이상의 새로운 특성으로 바꾼 것이다. 위에서 쓰던 예제를 원-핫 인코딩으로 다시 바꿔보자.
Scikit-learn - OneHotEncoder()
from sklearn.preprocessing import OneHotEncoder
# scikit-learn의 OneHotEncoder는 그냥 변수에 객체를 다시 할당해주기만 한다.
# toarray()를 쓰면 array형식의 output을 얻을 수 있는데, dataframe으로 다시 매핑할 수는 없다(기존 dataframe의 shape과 안맞으므로)
ohe = OneHotEncoder()
X_train = ohe.fit_transform(X_train).toarray()
X_test = ohe.transform(X_test).toarray()
X_train
# array([[0., 0., 1., ..., 1., 0., 0.],
# [1., 0., 0., ..., 0., 0., 1.],
# [1., 0., 0., ..., 0., 1., 0.],
# ...,
# [1., 0., 0., ..., 1., 0., 0.],
# [0., 0., 1., ..., 0., 1., 0.],
# [0., 1., 0., ..., 0., 0., 0.]])
Pandas - get_dummies()
더 좋은 방법은 pandas를 통해 아예 데이터프레임 형식으로 반환받는 것이다. 각 column 이름에 변수 특성을 명시해줘서 그냥 array 타입보다는 훨씬 보기 편하다.
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)
# 사실 이렇게 하는 것보다 그냥 X 자체를 가변수화한 다음에 train/test 나누는게 나을 것이다
print(list(X_train.columns))
# ['Favorite Color_Cool', 'Favorite Color_Neutral', 'Favorite Color_Warm', 'Favorite Music Genre_Electronic', 'Favorite Music Genre_Folk/Traditional', 'Favorite Music Genre_Hip hop', 'Favorite Music Genre_Jazz/Blues', 'Favorite Music Genre_Pop', 'Favorite Music Genre_R&B and soul', 'Favorite Music Genre_Rock', 'Favorite Beverage_Beer', "Favorite Beverage_Doesn't drink", 'Favorite Beverage_Other', 'Favorite Beverage_Vodka', 'Favorite Beverage_Whiskey', 'Favorite Beverage_Wine', 'Favorite Soft Drink_7UP/Sprite', 'Favorite Soft Drink_Coca Cola/Pepsi', 'Favorite Soft Drink_Fanta', 'Favorite Soft Drink_Other']
X_train.head()
너무 길어서 다 캡쳐는 못했지만 어쨋든 [기존 column명_속성값]으로 열이 rename되는 것을 확인할 수 있다. 이렇게 되면 dataframe의 size가 기하급수적으로 커지고, 크기에 비해 0값이 많기 때문에 sparse하지만 라벨 인코딩 방식의 문제들을 해결할 수 있다.
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 결정트리(Decision Tree) - 기본구조와 CART, ID3 알고리즘 (1) | 2021.10.03 |
|---|---|
| [ML] 모델 평가지표 - 오차행렬, PRC, ROC, AUC (3) | 2021.10.01 |
| [ML] 활성화 함수(Activation Function) 종류 정리 (0) | 2021.09.29 |
| [ML] 신경망에서의 Optimizer - 역할과 종류 (0) | 2021.09.28 |
| [ML] 손실함수와 경사하강법 - Loss function & Gradient Descent (0) | 2021.09.28 |



