지난 포스트에서 손실함수란 무엇이고, 어떻게 하면 손실함수의 최솟값이 되는 점을 찾는지 살펴보았다. 우리는 '최적화(optimization)'를 통해 파라미터를 잘 찾아서 문제 해결에 적합한 모델을 결정한다.
이번 장에서는 옵티마이저를 등장한 순서대로 소개해보려고 한다.


** 옵티마이저 계보 출처 - https://www.slideshare.net/yongho/ss-79607172
옵티마이저 (Optimizer)
손실함수를 줄여나가면서 학습하는 방법은 어떤 옵티마이저를 사용하느냐에 따라 달라진다. 경사하강법(gradient descent)은 가장 기본적이지만 가장 많이 사용되는 최적화 알고리즘이다. 손실 함수의 1차 도함수에 의존하는 first-order 최적화 알고리즘으로, 함수가 최소값에 도달할 수 있도록 어떤 방향으로 가중치를 업데이트해야 하는지 계산한다. 역전파(back propagation)를 통해 loss가 한 계층에서 다른 계층으로 전달되고, 다시 이 loss에 따라 모델의 파라미터가 수정되어 손실을 최소화할 수 있다.
경사하강법의 문제점
- 한번 학습할 때마다 모든 데이터셋을 이용한다. 즉, 손실함수의 최솟값을 찾아 나가기 위해 한 칸 전진할 때마다 모든 데이터를 다 훑는다는 것이다. 따라서 학습이 굉장히 오래 걸린다(최솟값을 찾는데 오래 걸린다).
- 학습률 정하기: 학습률(step size, 혹은 learning rate)가 너무 크다면, 최솟값을 계산하도록 수렴하지 못하고 loss 값이 계속 커지는 방향으로 진행될 수도 있다. 또는 아예 최솟값에 제대로 수렴하지 못할 수도 있다. 학습률이 너무 작다면, 최솟값을 찾는데 오랜 시간이 걸린다.

- Local Minima: 진짜 목표인 global minimum을 찾지 못하고 local minimum에 갖혀버릴 수도 있다. 어떤 파라미터 값에서는 local minimum에 도달하게 되는데, 이 지점 근처에서는 왼쪽이든 오른쪽이든 이동하면 loss가 증가한다.

- 메모리 한계: 모든 데이터를 한 번에 다 학습한다고 생각해보라. Hardware capacity에 따라 다르겠지만, '빅데이터'에 가까워질수록 가용 가능한 메모리에 다 올릴 수 없을 것이다.
이러한 문제들을 해결하기 위해 고안된 방법이 SGD이다.
1. SGD (Stochastic Gradient Descent; 확률적 경사하강법)
SGD는 전체 입력 데이터로 가중치와 편향이 업데이트되는 것이 아니라, 그 안의 일부 데이터만 이용한다. 전체 x, y 데이터에서 랜덤하게 배치 사이즈만큼 데이터를 추출하는데, 이를 미니 배치(mini batch)라고 한다. 이를 통해 학습 속도를 빠르게 할 수 있을 뿐만 아니라 메모리도 절약할 수 있다.
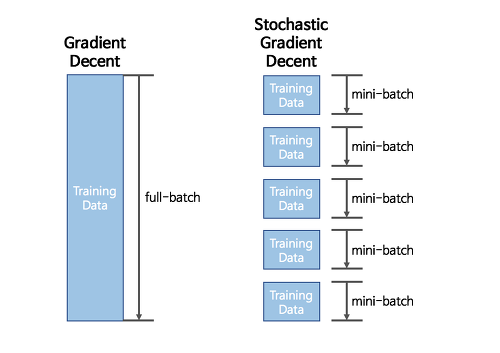
- epoch: 전체 데이터셋에 대해 한 번 학습을 완료하는 시점 (순전파/역전파 과정 거치기)
- batch size: 한 배치(묶음)에 있는 총 학습 샘플의 수
- iteration: 한 epoch를 완료하기 위해 실행하는 횟수
하지만 SGD도 GD의 고질적인 문제점인 학습률 설정, local minima 문제, oscillation 문제를 해결하진 못했다.
2. 모멘텀 (Momentum)
모멘텀은 SGD의 높은 편차를 줄이고 수렴을 부드럽게 하기 위해 고안되었다. 이는 관련 방향으로의 수렴을 가속화하고 관련 없는 방향으로의 변동을 줄여준다. 말 그대로 이동하는 방향으로 나아가는 '관성'을 주는 것이다.
- 이전 gradient들의 영향력을 매 업데이트마다
- momentum term

SGD에 비해 파라미터의 분산이 줄어들고 덜 oscillate한다는 장점이 있고, 빠르게 수렴한다. 하지만
3. NAG (Nesterov Accelerated Gradient)
모멘텀은 좋은 방법일 수 있지만, 모멘텀이 너무 높으면 알고리즘이 minima를 놓치고 건너뛰어버릴 우려가 있다. NAG는 '앞을 내다보는' 알고리즘이다. NAG에서는 momentum step을 먼저 고려하여, momentum step을 먼저 이동했다고 생각한 후 그 자리에서의 gradient를 구해서 gradient step을 이동한다.
식을 보면 gradient와 momentum step이 독립적으로 계산되는 것이 아님을 알 수 있다.

모멘텀에 비해 멈춰야 할 지점(minima)에서 제동을 걸기 쉽다. 일단 모멘텀으로 이동을 반 정도 한 후, 어떤 방식으로 이동해야 할 지 결정할 수 있다. 하지만 여전히 하이퍼 파라미터 값을 수동으로 결정해줘야 한다는 단점이 존재한다.
4. Adagrad
설명하고 있는 모든 옵티마이저의 단점 중 하나는 학습률이 모든 파라미터와 각 cycle에 대해 일정하다는 것이다. Adagrad는 각 파라미터와 각 단계마다 학습률
이 알고리즘의 기본적인 아이디어는 ‘지금까지 많이 변화하지 않은 변수들은 step size를 크게 하고, 지금까지 많이 변화했던 변수들은 step size를 작게 하자’ 라는 것이다. 자주 등장하거나 변화를 많이 한 변수들의 경우 optimum에 가까이 있을 확률이 높기 때문에 작은 크기로 이동하면서 세밀한 값을 조정하고, 적게 변화한 변수들은 optimum 값에 도달하기 위해서는 많이 이동해야할 확률이 높기 때문에 먼저 빠르게 loss 값을 줄이는 방향으로 이동하려는 방식이라고 생각할 수 있겠다.
- 출처 : http://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
Adagrad의 한 스텝을 수식화하면,
각 학습 파라미터에 대해 학습률이 바뀌기 때문에 수동으로 조정할 필요가 없지만, 이계도함수를 계산해야 하기 때문에 계산 비용이 많이 든다. 또, Adagrad에는 학습을 진행하면 진행할 수록 학습률이 줄어든다는 문제점이 있다.
5. RMSProp
RMSProp은 Adagrad에서의
Adagrad의

한 스텝이 지날때마다
6. Adam (Adaptive Moment Estimation)
Adagrad나 RMSProp처럼 각 파라미터마다 다른 크기의 업데이트를 진행하는 방법이다. Adam의 직관은 local minima를 뛰어넘을 수 있다는 이유만으로 빨리 굴러가는 것이 아닌, minima의 탐색을 위해 조심스럽게 속도를 줄이고자 하는 것이다. Adam은 AdaDelta와 같이 decaying average of squared gradients를 저장할 뿐만 아니라, 과거 gradient
이 보정된 값들을 가지고 파라미터를 업데이트한다. 기존에
loss가 최솟값으로 빠르게 수렴하고 vanishing learning rate 문제, high variance 문제를 해결하였다. 계산 비용이 많이 든다는게 단점이라면 단점일 것이다.
참고자료:
https://towardsdatascience.com/optimizers-for-training-neural-network-59450d71caf6
http://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
'AI > Machine Learning' 카테고리의 다른 글
| [ML] 결정트리(Decision Tree) - 기본구조와 CART, ID3 알고리즘 (1) | 2021.10.03 |
|---|---|
| [ML] 모델 평가지표 - 오차행렬, PRC, ROC, AUC (3) | 2021.10.01 |
| [ML] 범주형 변수 처리 - Label Encoding, One-hot Encoding (0) | 2021.09.29 |
| [ML] 활성화 함수(Activation Function) 종류 정리 (0) | 2021.09.29 |
| [ML] 손실함수와 경사하강법 - Loss function & Gradient Descent (0) | 2021.09.28 |



