[강화학습] CH02-2. 정책과 가치 함수 - policy, value function
1. 상태 가치 함수 (State Value Function) in MRP
상태 \(s \)의 밸류(value) 혹은 가치를 숫자 하나로 평가하고 싶다면 그 시점으로부터 미래에 일어날 보상을 기준으로 평가해야 한다. 즉, \( s\)부터 시작하여 리턴(return; 자세한 설명은 이전 포스트 참조)을 측정하면 된다.
$$ v(s) = E[G_t|S_t=s] $$
리턴의 값은 확률적인 요소에 의하여 다음 상태가 정해지므로, 같은 \(s \)에서 출발해도 리턴 값이 달라질 수 있다. 따라서 리턴의 기댓값을 사용해 value를 계산한다.
episode sampling
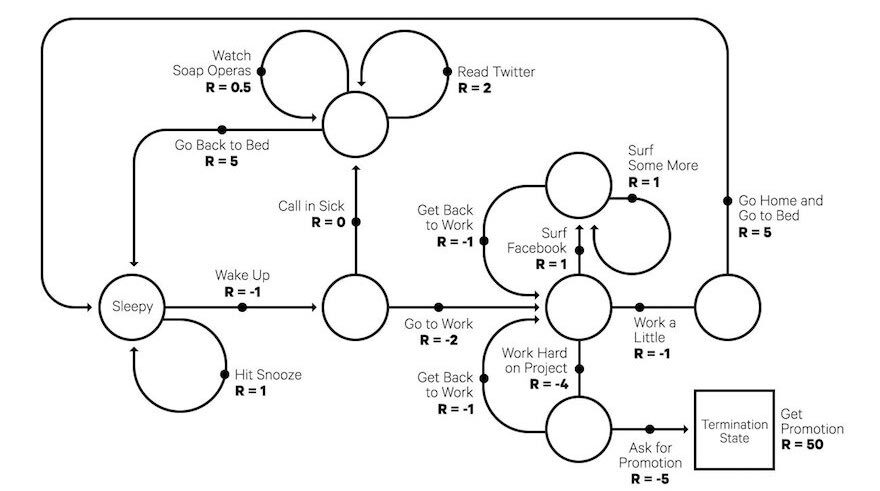
시작 상태(initial state)부터 종료 상태(terminal state)까지 에이전트가 거친 상태, 행동, 보상의 sequence를 에피소드라고 했다. 그런데 하나의 에피소드 안에서 방문하는 상태들은 매번 다르다. 가령, 위의 그림에서 Sleepy라는 상태에서 Wake Up으로 넘어갈 수도 있고, Hit Snooze를 방문해 다시 잠에 들수도 있다. 일어나서 출근한 후에도 Surf Facebook, Work a Little, Work Hard on Project 등 에이전트가 거칠 수 있는 상태 후보군이 많다. 즉, 어떤 에피소드를 선택하느냐에 따라 리턴이 달라진다.
MRP에서 발생할 수 있는 에피소드는 무한히 많기 때문에, 모든 에피소드마다 해당 에피소드가 발생할 확률과 그 때의 리턴 값을 곱해 더해주는 것은 불가능하다. 따라서 sampling(표본 추출)으로 얻은 리턴의 평균을 통해 value를 근사하게 계산하는 접근법으로 state value function을 정의할 수 있다.
2. 정책과 정책 함수 (policy, policy function) in MDP
각 상태에서 에이전트가 어떤 액션을 선택할지 정해주는 함수를 정책(policy) 혹은 정책 함수(policy function)라고 한다.
$$ \pi(a|s) = P[A_t=a | S_t = s] $$
위 식을 풀어쓰면 '상태 \(s \)에서 액션 \( a \)를 선택할 확률'이라고 할 수 있다. 에이전트의 목표는 보상의 합을 최대화하는 정책을 찾는 것이다.
상태 가치 함수 (State Value Function) in MDP
$$ v_\pi(s) = E_\pi[r_{t+1} + \lambda r_{t+2} + \lambda^2 r_{t+3} + ... | S_t = s] = E_\pi[G_t | S_t = s] $$
MDP에서는 MRP에서와는 달리 에이전트의 액션이 도입되었기 때문에 에이전트의 정책 함수에 따라서 얻는 리턴이 달라진다. 즉, MDP의 value function은 정책 함수에 의존적이며, value function을 정의하기 위해서는 먼저 정책 함수 \( \pi \)가 정의되어야 한다. 따라서 식에 정책을 나타내는 \( \pi \)가 추가되었으며, MDP의 value function은 \(s \)부터 끝까지 \( \pi \)를 따라 움직일 때 얻는 리턴의 기댓값으로 정의된다.
액션 가치 함수 (State-Action Value Function) in MDP
액션 가치 함수는 각 상태에서의 액션을 평가하는 함수이다(마치 state value function이 어떤 상태가 주어졌을 때 해당 상태의 가치를 평가하는 함수인 것처럼).
$$ q_\pi(s, a) = E_\pi[G_t | S_t = s, A_t = a] $$
state value function이 \( v(s) \)로 표현되었다면 state-action value function은 \( q(s, a) \)로 표현한다. state-action value function은 \(s\)에서 \(a\)를 선택하고, 그 이후에는 쭉 \( \pi \)를 따라 움직일 때 얻는 리턴의 기댓값이기 때문이다.
- state value function : \(s \)부터 끝까지 \( \pi \)를 따라 움직일 때 얻는 리턴의 기댓값
- state-action value function : \(s\)에서 \(a\)를 선택하고, 그 이후에는 \( \pi \)를 따라 움직일 때 얻는 리턴의 기댓값
state-action value function은 함수에 input으로 상태 \(s\)와 선택한 액션 \(a\)가 함께 들어간다. 요컨대 \(s \)에서 \(a_1 \)을 선택하는 것과, \(a_2 \)를 선택하는 것은 전혀 다른 상황이기 때문이다. 따라서 \(s\)와 \(a\)의 페어를 고정시켜 인풋으로 넣어주게 된다. 즉, \(v_\pi(s) \)를 계산할 때는 \( s\)에서 \( pi \)가 액션을 선택하는 반면, \( q_\pi(s, a) \)를 계산할 때는 \(s\)에서 강제로 \(a\)를 선택한다.
3. Prediction & Control

- prediction : \( \pi \)가 주어졌을 때 각 상태의 value를 평가하는 문제
- control : 최고의 정책 \( \pi^* \)를 찾는 문제
MDP를 풀 때, 즉 \( (S, A, P, R, \lambda) \)가 주어졌을 때 두 가지의 목적을 세워볼 수 있다. 하나는 prediction으로, 임의의 정책 \( \pi \)에 대해 각 상태의 value \( v_\pi(s) \)를 구하는 것이고, 다른 하나인 control은 최적 정책(optimal policy) \( \pi^* \)을 찾는 것이다. optimal policy는 시간이 경과함에 따라 최대의 보상을 위해 각 상태에서 취할 수 있는 최선의 액션을 정해준다(참고로 optimal policy \( \pi^* \)를 따를 때의 state value function을 최적 가치 함수(optimal value function)이라고 부르고, \( v^* \)라고 표기한다).