지도학습 vs 비지도학습 vs 강화학습
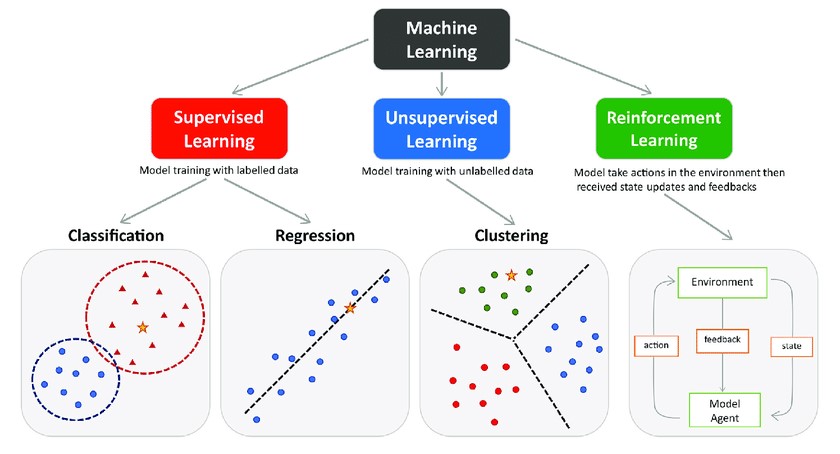
- 지도학습(supervised learning): 정답(라벨)이 지정된 데이터를 사용해 모델 학습
- 비지도학습(unsupervised learning): 정답(라벨)이 없는 데이터를 사용해 모델 학습
- 강화학습(reinforcement learning): 순차적 의사결정 문제에서 누적 보상을 최대화 하기 위해 시행착오를 통해 행동을 교정하는 학습과정
지도학습, 비지도학습과 강화학습은 모두 기계 학습(machine learning)에 속하는 개념이다. 흔히 머신러닝과 인공지능(AI)를 혼용해 쓰곤 하는데, 엄밀히 말하면 머신러닝은 AI를 구현하는 하나의 방법론이라 할 수 있다. AI는 인위적으로 사람과 같이 사고할 수 있는 지능을 폭넓게 지칭하는 말이고, 머신러닝은 컴퓨터를 통해 모델을 학습시킴으로써 AI를 구현하고자 한 것이라고 보면 쉽다.
지도학습과 비지도학습은 학습 데이터에 정답, 즉 라벨이 있는지 그 유무에 따라 나눌 수 있다. 강화학습은 이와는 좀 다른 방식이다. 위에서 강화학습을 '순차적 의사결정 문제에서 누적 보상을 최대화 하기 위해 시행착오를 통해 행동을 교정하는 학습 과정'이라고 정의했다. 이 문장을 쪼개 강화학습이란 무엇인지 자세하게 알아보자.
1. 순차적 의사결정 문제 (sequential decision making)
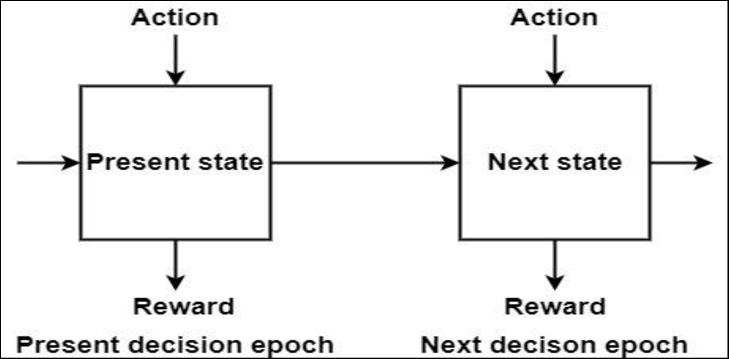
인공지능에서 순차적 의사결정은 환경의 역학(dynamics)을 고려하여 문제의 일부를 해결해야 할 때까지 지연시키는 알고리즘을 말한다. 의사 결정에 대한 절차적 접근 방식 또는 단계별 의사 결정 이론으로 설명할 수 있다. 순차적 의사결정은 결과적으로 시간간 선택 문제를 야기하며, 초기 결정은 나중에 이용 가능한 선택에 영향을 미친다(Sequential decision making has as a consequence the intertemporal choice problem, where earlier decisions influences the later available choices).
- 출처 : https://en.wikipedia.org/wiki/Sequential_decision_making
가령 샤워하기와 같은 간단한 과정이라 하더라도 이를 성공적으로 마치기 위해서 우리는 몇 가지 의사결정을 순차적으로 해줘야 한다. 각 행동에 따라 상황이 변하고, 이렇게 변한 상황에 따라 하는 행동이 또 다음 상황에 영향을 주는, 즉 연이은 행동을 잘 선택해야 하는 문제가 '순차적 의사결정 문제'라고 할 수 있다.
2. 누적 보상 최대화 (cumulative reward maximization)
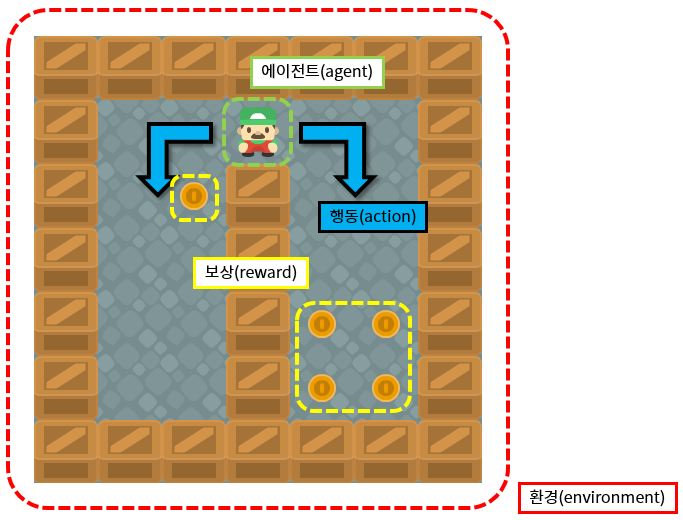
- 보상(reward): 의사결정을 얼마나 잘하고 있는지 알려주는 신호
- 누적 보상(cumulative reward): 학습의 과정에서 받는 보상의 총합
보상의 3가지 특징
- 어떻게 X 얼마나 O
: 보상은 본질적으로 지도학습의 라벨과는 다르다. 강화학습에서 보상은 어떻게 해야 높은 보상을 얻을 수 있을지 알려주는 것이 아니라, 어떠한 행동을 하면 그것에 대해 '얼마나' 잘 하고 있는지 수치적으로 알려줄 뿐이다(그래서 '시행착오'라는 단어를 쓴다). 보상은 어떤 행동을 해야할지 직접적으로 알려주지는 않지만, 사후적으로 보상이 낮았던 행동들은 덜 하고, 보상이 높았던 행동들은 더 하면서 보상을 최대화하도록 행동을 수정해나갈 수 있도록 한다. - 스칼라
: 보상은 벡터(vector)가 아니라 스칼라(scalar)이다. 즉, 하나의 목적을 가져야 한다. - 희소하고 지연된 보상
: 보상은 선택했던 행동의 빈도에 비해 가끔 주어지거나, 행동이 발생한 후 한참 뒤에 나올 수도 있다. 이 때문에 행동과 보상의 연결이 어려워진다. 가령 축구를 할 때, 이기면 +1 지면 -1의 형태로 보상을 정의할 수 있다. 하지만 평균적으로 수많은 액션, 뒤로 갔다 앞으로 갔다 등의 행동을 해야 한 경기가 끝이 난다. 그러면 행동 수백개와 보상 1개가 연결이 되므로, 어떤 행동이 좋았고 어떤 행동이 안 좋았는지 교정하기 어려워진다. 보상이 희소할수록 학습이 어려워지는 이러한 문제를 해결하기 위해 최근 등장한 것이 강화학습에서의 밸류 네트워크(value network)이다.
3. 에이전트와 환경
에이전트(agent)를 강화학습의 주체라고 한다면 환경(environment)는 에이전트를 제외한 모든 요소라고 할 수 있다. 다시 말해, 에이전트가 어떤 행동을 했을 때, 그 결과에 영향을 아주 조금이라도 미치는 모든 요소들을 환경이라고 한다.
위에서 설명한 순차적 의사결정 문제를 에이전트와 환경을 통해 설명한다면, '에이전트가 액션(action)을 하고 그에 따라 상황이 변하는 루프(loop)가 끊임없이 반복되는 것'이라고 할 수 있다.
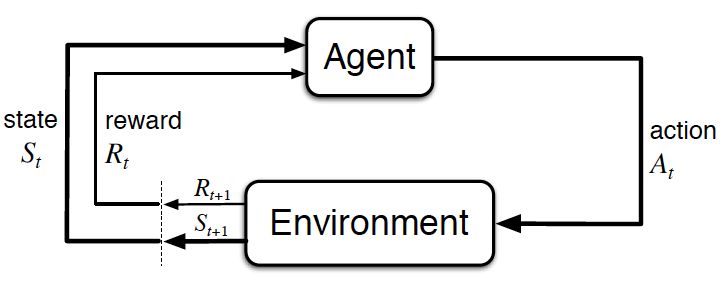
에이전트의 입장에서 loop는 다음과 같은 과정을 거친다.
1. 현재 상황 \( s_t \)에서 어떤 액션을 해야 할지 \( a_t \)를 결정
2. 결정된 행동 \( a_t \)를 환경으로 보냄
3. 환경으로부터 그에 따른 보상 \( r_{t+1} \)과 다음 상태 \(s_{t+1} \)의 정보를 받음
환경의 입장에서는 다음과 같다.
1. 에이전트로부터 받은 액션 \( a_t \)를 통해 상태 변화(state transition)을 일으킴
2. 그 결과 상태는 \(s_t\) -> \(s_{t+1} \)로 바뀜
3. 에이전트에게 줄 보상 \( r_{t+1} \)도 함께 계산
4. \( s_{t+1} \)과 \( r_{t+1} \)을 에이전트에게 전달
- 상태(state, \( s \)): 현재 상태에 대한 모든 정보를 숫자로 표현한 것
- 타임 스텝(time step, \(t \)): 순차적 의사결정 문제에서의 이산적인(discrete) 시간의 단위
'AI > Reinforcement Learning' 카테고리의 다른 글
| [강화학습] CH02-2. 정책과 가치 함수 - policy, value function (0) | 2022.07.12 |
|---|---|
| [강화학습] CH02-1. 마르코프 결정 프로세스(MDP; Markov Decision Process) (0) | 2022.07.05 |

