[MLOps] Elasticsearch의 BM25 스코어 알고리즘 이해하기
쿼리 컨텍스트는 엘라스틱에서 지원하는 다양한 스코어 알고리즘을 사용할 수 있는데, 기본적으로 BM25 알고리즘을 이용해 relevance score를 계산한다. Relevance score는 쿼리와 도큐먼트의 유사도를 표현하는 값으로, 점수가 높을수록 찾고자 하는 도큐먼트에 가깝다는 사실을 의미한다.
쿼리를 요청하고 스코어가 어떤 식으로 계산되었는지 알아보기 위해 쿼리에 explain 옵션을 추가해보았다.
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"products.product_name": "Pants"
}
},
"explain": true
}
- 결과창 -
{
#길어서 줄임
# ....
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 8.268259,
"hits" : [
{
"_shard" : "[kibana_sample_data_ecommerce][0]",
"_node" : "t52zSRNKRDWjZJpRI3qF9A",
"_index" : "kibana_sample_data_ecommerce",
"_type" : "_doc",
"_id" : "wRP0iIABcyMg_XUDPAA0",
"_score" : 8.268259,
"_source" : {
"category" : [
"Men's Shoes",
"Men's Clothing"
],
"currency" : "EUR",
"customer_first_name" : "Robert",
"customer_full_name" : "Robert Cross",
"customer_gender" : "MALE",
"customer_id" : 29,
"customer_last_name" : "Cross",
"customer_phone" : "",
"day_of_week" : "Wednesday",
"day_of_week_i" : 2,
"email" : "robert@cross-family.zzz",
"manufacturer" : [
"Elitelligence",
"Low Tide Media"
],
"order_date" : "2022-05-04T11:51:22+00:00",
"order_id" : 568578,
"products" : [
{
"base_price" : 46.99,
"discount_percentage" : 0,
"quantity" : 1,
"manufacturer" : "Elitelligence",
"tax_amount" : 0,
"product_id" : 17925,
"category" : "Men's Shoes",
"sku" : "ZO0520005200",
"taxless_price" : 46.99,
"unit_discount_amount" : 0,
"min_price" : 24.43,
"_id" : "sold_product_568578_17925",
"discount_amount" : 0,
"created_on" : "2016-12-14T11:51:22+00:00",
"product_name" : "Boots - tan",
"price" : 46.99,
"taxful_price" : 46.99,
"base_unit_price" : 46.99
},
{
"base_price" : 32.99,
"discount_percentage" : 0,
"quantity" : 1,
"manufacturer" : "Low Tide Media",
"tax_amount" : 0,
"product_id" : 16500,
"category" : "Men's Clothing",
"sku" : "ZO0421104211",
"taxless_price" : 32.99,
"unit_discount_amount" : 0,
"min_price" : 16.82,
"_id" : "sold_product_568578_16500",
"discount_amount" : 0,
"created_on" : "2016-12-14T11:51:22+00:00",
"product_name" : "Casual Cuffed Pants",
"price" : 32.99,
"taxful_price" : 32.99,
"base_unit_price" : 32.99
}
],
#.....
"_explanation" : {
"value" : 8.268259,
"description" : "weight(products.product_name:pant in 594) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 8.268259,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 7.1974354,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 3,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4675,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.52217203,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 5.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 7.3161497,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
가장 높은 스코어인 8.268259를 갖고 id가 wRP0iIABcyMg_XUDPAA0인 첫 번째 도큐먼트 출력 결과만 가져왔다. 계산식은 이미 explanation 항목에 서술되어 있다.
1. TF-IDF
TF-IDF에 대해서는 이미 아래 포스트에서 다룬 적이 있다.
[DL] 자연어 처리에서의 텍스트 표현 - 단어 임베딩(Word Embedding)
Text Vectorization 어떻게 자연어를 컴퓨터에게 인식시킬 수 있을까? 컴퓨터는 모든 값을 읽을 때 0 또는 1, 즉 이진화된 값으로 받아들인다. 따라서 텍스트도 마찬가지로 수치형 텐서로 변환하는 과
heeya-stupidbutstudying.tistory.com
TF-IDF는 현재까지도 term relevancy를 계산하는데 자주 쓰이기는 하지만, 다음과 같은 문제점들이 있다:
- 문서의 길이를 고려하지 못한다.
총 100개의 단어 중 "축구"라는 단어가 10번 나오는 문서와, 총 1000개의 단어 중 "축구"라는 단어가 20번 나오는 문서가 있다고 해보자. 어떤 문서가 "축구"와 더 관련이 있을까? term frequency만 고려한다면 후자의 문서이겠지만, 우리는 직관적으로 전자의 주제가 "축구"일 가능성이 더 높다는 것을 안다. - term frequency is not saturated.
IDF가 일반적인 단어에 대해 불이익을 주긴 하지만, 그런 단어들을 아주 많이 포함하는 문서가 몇개 있다고 하면 어떻게 될까? TF 값이 아주아주 커져서 불용어를 많이 포함하는(다시 말하면 irrelevant한) 문서들을 boost할 것이다.
이러한 이유에서 BM25를 state-of-art similarity function이라고 말한다.
2. BM25 (Best Match 25)
엘라스틱서치는 5.x. 이전 버전에서는 TF-IDF 알고리즘을 사용했으나 엘라스틱 5.x부터 BM25 알고리즘을 default로 사용한다. BM25 알고리즘은 검색, 추천에 많이 사용되는 알고리즘으로 term frequency와 inverse document frequency 개념에 문서 길이를 고려한 알고리즘이다(TF-IDF의 variation). 엘라스틱서치의 검색 근간이 되는 lucene이 기본 스코어 알고리즘으로 BM25를 채택하면서, lucene을 코어로 사용하는 엘라스틱서치도 변경하게 되었다고 한다.

- \(boost\) : 엘라스틱이 지정한 고정값 상수(2.2)
- \(idf\) : 역문서 빈도 (inverse document frequency)
- \(tf\) : 용어 빈도 (term fequency)
2-1. IDF
특정 용어가 얼마나 자주 등장했는지를 의미하는 지표이다. 일반적으로 자주 등장하는 'to', 'the'와 같은 관사는 중요하지 않을 확률이 높다. 마찬가지로 '그리고', '그러나' 같이 문장을 이어주는 접속부사도 모든 도큐먼트에 자주 등장하지만 큰 의미를 가지지는 않는다. 그래서 도큐먼트 내에서 발생 빈도가 적을수록 가중치를 높게 주는데 이를 역문서 빈도라고 한다. 중요한 것은 한 도큐먼트 안에서 용어가 몇 번 등장하는지는 고려하지 않고, 전체 도큐먼트 중 해당 용어가 등장하는 도큐먼트 수만을 고려한다는 것이다.
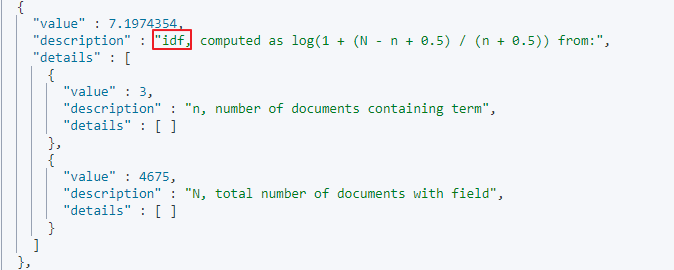
- \(n \) : 검색한 용어가 포함되어 있는 도큐먼트의 수
- \(N \) : 인덱스 전체의 도큐먼트의 수
2-2. TF
특정 용어가 하나의 도큐먼트에 얼마나 많이 등장했는지를 의미하는 지표이다. 일반적으로 특정 용어가 도큐먼트에서 많이 등장한다면 그 용어는 도큐먼트와 연관되어 있을 확률이 높다.
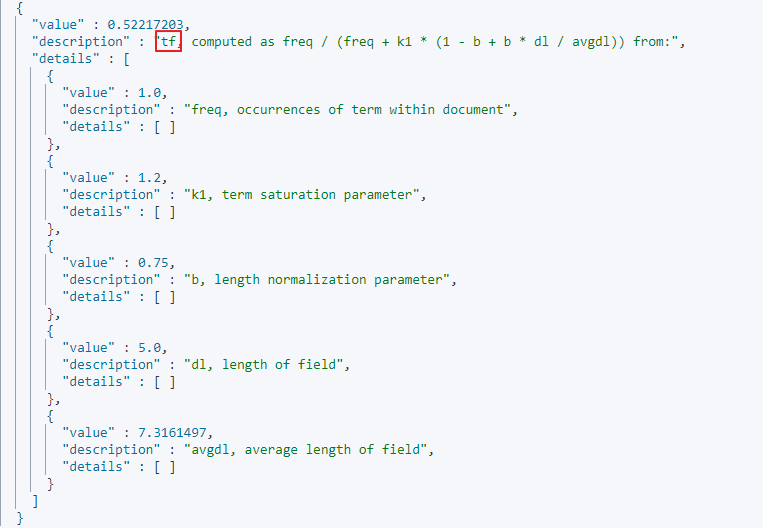
- \( freq\) : 도큐먼트 내에 용어가 등장한 횟수
- \( k1, b \) : 알고리즘 정규화 가중치 (엘라스틱서치에서 정한 상수값)
- \( dl \) : 필드 길이
- \( avgdl \) : 전체 도큐먼트에서의 평균 필드 길이 (인덱스 내의 모든 도큐먼트를 토큰화 했을 때의 도큐먼트 당 갖는 평균 토큰 수)
TF-IDF vs BM25
맨 처음 섹션에서 TF-IDF의 shortcommings에 대해 언급했었다. BM25 알고리즘은 이에 대해 어떤 advantage를 얻어가는지 살펴보자.
TF

TF의 영향이 줄어든다. TF에서는 용어의 출현 빈도가 높아질수록 스코어가 계속 높아지는 반면, BM25에서는 특정 값으로 수렴한다.
IDF
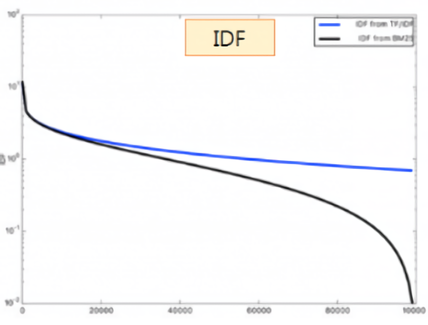
반대로 IDF의 영향이 커진다. BM25에서는 IDF 값이 커질수록 스코어가 0으로 급격히 수렴한다. 이는 불용어의 영향을 최소화할 수 있는 방법이다.
norm
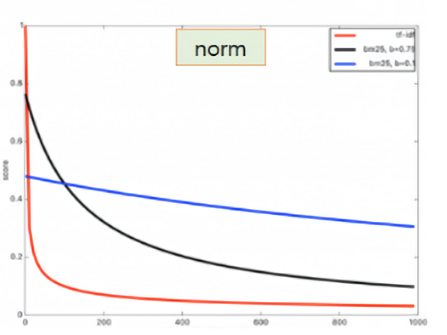
문서 길이의 영향이 줄어든다. BM25에서는 문서의 평균 길이를 \(dl \)과 \( avgdl \) 변수를 통해 계산하는데, \( dl\)이 작고 \(avgdl \)이 클수록 TF 값이 높게 나오므로, 짧은 글에서 찾고자 하는 용어가 포함될수록 가중치가 높아진다.
https://www.infoq.com/articles/similarity-scoring-elasticsearch/