[논문리뷰] YAKE! - Keyword extraction from single documents using multiple local features
Supervised vs Unsupervised
자연어 처리, 정확히는 키워드 추출과 관련된 연구 중에서 supervised approaches는 문서에서 중요한 단어와 그렇지 않은 단어들을 구분하는 모델을 학습하기 위한 사실상의 표준 방법론으로 자리매김했다. 머신러닝 알고리즘은 몇 가지 이점을 제공하지만, 다음과 같은 단점들도 존재한다
- requires rather long training process
- demand large manually annotated collection of documents
그니까 머신러닝 혹은 딥러닝 모델을 학습시키려면, 대량의 데이터(라벨링이 된)와 그것을 학습할 충분한 시간이 필요한데, 상황에 따라 이것이 불가능한 경우도 있다. 대규모의 코퍼스를 수집하는 것도 demanding한 일이거니와 그것에 라벨을 일일이 다는 것은 머신러닝 모델을 현업에 활용하는데 있어 에러사항이 되기도 한다.
따라서 이번 포스트에서는 지도 학습의 대체제로 사용할 수 있는 unsupervised learning approach, 그 중에서도 신경망을 기반으로 하지 않는 lightweight statistical method인 YAKE를 소개해보려 한다.
2018년 처음 공개되어 2019년의 revision을 거쳐 2020년 Elsevier 저널에 투고된 버전을 바탕으로 쓴 글임을 미리 밝힌다. 정식 파이썬 패키지와 데모, api도 제공하고 있으니 깃헙 참고.

1. Introduction
\( m\)개의 단어 \( [w_1, w_2, ..., w_m ] \)이 있는 문서가 주어지면, 키워드 추출은 문서를 포괄적으로 나타낼 수 있는 명사구를 찾는 작업이다. 이러한 각 구문(phrases)은 문서에서 연속된 단어로 구성되므로 문서에 나타난 모든 후보 구문(candidate phrases)에 대한 일반적인 ranking 문제로 볼 수 있다. 따라서 일반적인 키워드 추출 파이프라인은 대상 문서 \( d\)에 대한 candidate phrases \(P_d\)를 구성하고, \(d\)의 모든 개별 단어에 대한 중요도 중요도 점수(importance scores)를 계산하는 것으로 구현된다.
즉, 개별 단어 단위의 점수를 구하는 것이 중요한데, statistical method와 graph-based method 두 가지 방법론으로 나눌 수 있다.
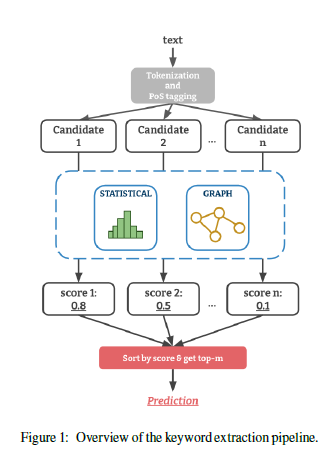
Statisical methods는 개별 문서에서 중요한 키워드를 식별하기 위해 term co-occurence(동시 등장)나 빈도와 같은 local 텍스트 피처와 통계 정보에 의존한다. 대표적으로는 고전적인 TF-IDF부터 KP-Miner, RAKE 등이 있다. 논문은 다음과 같은 장점들을 YAKE 개발의 motivation으로 꼽는다.
- does not require any annotated text corpora or training stage (<-> supervised learning)
- rely on single documents, thus making it possible to quickly apply solution to a myriad of scenarios
- do not resort to linguistic tools or external sources (<-> unsupervised graph-based methods)
- can apply to various different languages or domains in a plug and play nature
2. YAKE! algorithm
2-1. Text pre-processing and candidate term identification
segtok rule-based sentence segmenter을 이용해 문서를 문장 단위로 나눈다(segtok은 텍스트를 문장 단위로 나눠주는 segmenter와 문장을 토큰 단위로 나눠주는 tokenizer가 있다. 자세한 사항이 궁금하다면 segtok 개발자의 블로그 글 참고). 그리고 segtok segmenter의 web_tokenizer을 이용해 이 문장을 다시 chunck 단위로 쪼개는데, 이 chunck들은 소문자로 변환된 후 tag delimiters가 첨부된다.

- \(<d> \) : 숫자
- \(<u> \) : 나눌 수 없는 구문 (ex. 메일주소, 숫자+문자 구문 등)
- \(<a> \) : 약어(AIDS처럼 단어의 머리글자로 만든 말)
- \(<U> \) : 대문자로 이루어진 단어
- \(<p> \) : 위에 속하지 않는 나머지
그 다음에, 입력받는 언어에 대해 static list로 정의된 stopwords(불용어)를 사용해 잠재적으로 의미 없는 토큰들을 탐지한다. (없애는 것 아님 주의!!!) 이 전처리 단계의 결과는 문장의 list이며, 각 문장은 annotation이 달린 chunk로 나뉜다.
2-2. Feature extraction
전처리 단계가 끝나면 structure(구조), term fequencies(용어 빈도) 및 co-occurence(동시 등장)에 focusing하는 특징들을 추출한다. 논문은 candidate term이 1-gram token일 때 각 term의 특성을 가장 잘 포착할 수 있는 5가지 피처셋을 제안한다.
해당 용어들은 피처 설명할 때 자주 나오니 외워두면 좋다.
- \( TF \) : term frequency
- \( TF_a \) : term frequency of acronyms
- \( TF_U \) : term frequency of uppercase terms
(1) Casing \( (T_{case}) \)
기본적인 근거는 "대문자 용어가 소문자 용어에 비해 문서에 대해 더 relevant할 가능성이 크다"이다. 사람이 텍스트를 읽을 때도 대문자로 시작하는 용어에 특별히 주의를 기울이는 것처럼..! 따라서 candidate term의 casing aspect는 다음과 같이 계산될 수 있다:
$$ T_{case} = \frac{max(TF(U(t)), TF(A(t)))}{ln(TF(t))} $$
- \( TF(U(t)) \) : candidate term \(t\)가 대문자로 표시된 횟수
- \( TF(A(t)) \) : candidate term \(t\)가 약어로 표시된 횟수
따라서, candidate term이 대문자로 더 자주 표시될수록 더 중요하게 고려되고, \( T_{case} \)의 값도 커진다.
(2) Term position \( (T_{position}) \)
기본적인 근거는 "중요한 키워드는 문서의 맨 처음 부분에 나타나는 경향이 있는 반면, 중요하지 않은 단어들은 문서의 중간이나 끝에서 발생한다"이다. 논문에 따르면, 이는 특히 텍스트 맨 위에 높은 수준의 중요한 키워드를 집중하는 경향이 있는 두 종류의 출판물인 뉴스 기사와 과학 저널 등에서 명백하다고 한다. 그래서 단어의 문서 내 position을 고려해야 하는데, 저자는 문장에서 단어의 위치가 아닌 단어를 포함하는 문장의 위치에 집중한다. \( Sent_t \)는 candidate term이 포함된 문장의 위치 집합으로 정의된다.
즉, 다음의 식
$$ T_{position} = ln(ln(3+Median(Sent_t))) $$
으로 계산된 \( T_{position} \)의 값이 작을수록 candidate term이 문서 앞단에 등장하는 횟수가 많다는 것이다. 반대로 해당 값이 클수록 candidate term이 문서의 뒷단에 자주 등장한다는 얘기로, less relevant 할 것이다.
(3) Term frequency normalization \( (TF_{Norm}) \)
"candidate term이 문서 내에서 발생하는 빈도가 클수록 그 중요성이 커진다". 한편, 이것은 중요도가 term의 빈도와 완전히 비례관계에 있다는 것을 의미하지는 않는데, 긴 문서에서 빈도의 편향을 방지하기 위해 candidate term \( t\)의 \(TF\)값을 빈도의 평균\( (MeanTF)\)에 표준편차를 곱한 값으로 나눈다.
$$ TF_{Norm} = \frac{TF(t)}{MeanTF + 1*\sigma } $$
저자의 목적은 빈도가 평균보다 높고, 표준편차에 의해 주어진 일정 정도의 분산으로 균형을 이루는 모든 candidate term을 평가하는 것이다. 이를 위해 \(MeanTF\)와 stopwords가 아닌 단어들의 표준편차만 고려할 수 있도록 설계함으로써, 이 두 구성요소의 계산이 stopwords의 높은 빈도수의 영향을 받지 않도록 보장한다.
(4) Term relatedness of context \( (T_{Rel}) \)
위에서 stopwords를 detect한 뒤 제거하는 것은 아니라고 말했었는데, YAKE는 static list의 stopwords를 사용하기 때문에 non-relevent하다고 해서 단순히 제거해버리는 것은 옳지 않을수도 있다. 이 섹션에서는 특정 context와 관련하여 candidate term의 분산\((D)\)을 결정하는 것을 목표로 하는 통계적 특징에 대해 설명한다.
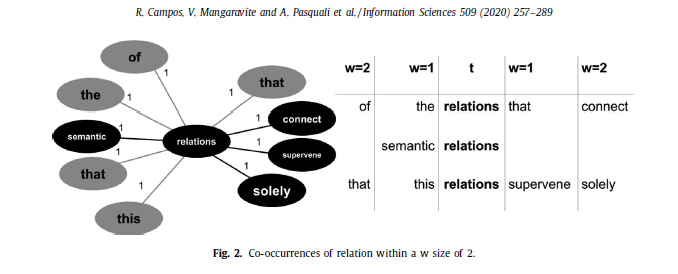
위 그림은 window size \( w \) 2 내에서 candidate term "relations"와 함께 등장하는 다양한 용어들을 보여준다. 오른쪽 표에서 \(w\)의 크기에 따라 "relations"와 함께 발생하는 단어들은 왼쪽 그래프와 같이 매핑될 수 있는데(그래프의 왼쪽과 오른쪽에 위치한 단어들은 각각 "relations"와 선후관계에 따라 등장한 단어들이다), 왼쪽 항에 있는 5개의 단어가 다 서로 다르고(분산이 높다) 오른쪽 항에 위치한 단어들도 마찬가지인 것을 알 수 있다. 논문에서 깔고 가는 전제는 "양쪽에 candidate term \(t\)와 함께 발생하는 서로 다른 단어들의 개수가 많아질수록, \(t\)는 less significant해진다"이다(assumption of Machado et al.(2009)). 따라서 "relations"은 전체적인 컨텍스트에서 중요하지 않은 용어라고 판단할 수 있다.
DL 분산은 다음과 같이 계산할 수 있다.
$$ DL[DR] = \frac{|A_{t, w}|}{\sum _{k\in A_{t, w}} CoOccur_{t, k}} $$
여기서 \( |A_{t, w}| \)는 서로 다른 용어의 수를 나타내며, 용어는 \(w \) 크기의 미리 정의된 window 내에서 candidate term의 왼쪽[오른쪽]에 나타나는 parsable content, acronym, 혹은 uppercase word이다.
그런 다음, DL과 DR은 candidate term의 빈도를 문서에서 나타나는 모든 candidate term의 최대 빈도\((TF)\)로 나눈 값에 곱하여져, 높은 빈도로 발생하고(stopwords가 그러하듯이) 좌우 양쪽에서 많은 다른 용어들과 함께 등장하는 \(t\)에 불이익을 준다. 즉,
$$ T_{Rel} = 1+(DL+DR...)*\frac{TF(t)}{MaxTF} $$
실제로, candidate term이 less relevant할수록 이 피처의 점수는 더 높아진다. 따라서 stopwords와 마찬가지로 non-discriminant term이 더 높은 점수를 얻는 경향이 있다.
(5) Term different sentence \( (T_{sentence}) \)
이 피처는 candidate term이 다른 문장 내에서 나타나는 빈도를 수량화한다. 기저에 깔린 가정은 "다른 문장에 많이 등장하는 \(t\)는 문서 내에서 중요한 키워드일 확률이 더 높다"이다. 이는 다음의 방정식으로 계산된다:
$$ T_{sentence} = \frac{SF(t)}{number \; of \; Sentences} $$
\( SF(t) \)는 candidate term \(t\)가 나타나는 문장의 수이고 number of Sentences는 총 문장 수이다. 결과적으로 \( [0, 1] \)의 범위를 갖게 된다.
2-3. Computing term score
위에서 정의했던 5개의 피처를 모두 조합해 unique한 점수 \( S(t) \)를 구한다.
$$ S(t) = \frac{T_{Rel}*T_{position}}{T_{case}+\frac{TF_{Norm}}{T_{Rel}}+\frac{T_{sentence}}{T_{Rel}}} $$
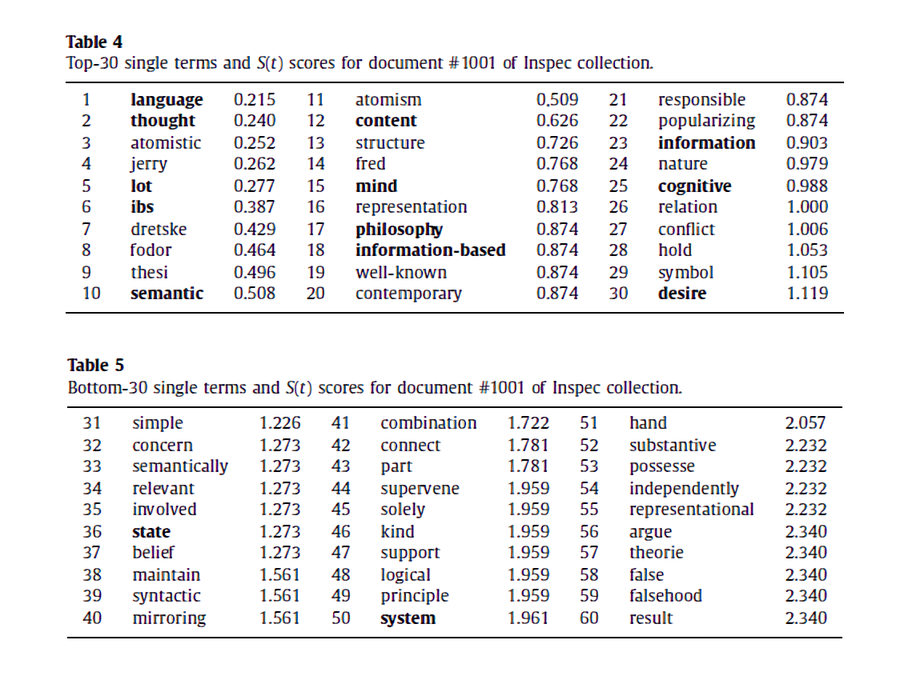
값이 작으면 작을수록, 1-gram term \(t\)는 문서 내에서 significant하다. 논문에서는 다음과 같은 실험 결과를 제시하는데, 위쪽에 위치한 Table 4는 \( S(t) \)가 낮은 순서대로 top-30을 뽑은 것이고, 아래에 위치한 Table 5는 높은 순서대로 top-30을 뽑은 것이다. 확실히 점수가 높은 용어들은 범용적으로 쓰이는 term이고, document-specific하지 못하다는 것을 알 수 있다.
2-4. n-gram generation and computing candidate keyword score
끝날 때까지 끝난 게 아니다... 위에서는 1-gram term을 기준으로 candidate term을 뽑아냈지만, 문서가 모두 개별 단어로만 이루어 진 것은 아니다(ex. 금융 뉴스에서 자주 나오는 용어 "Dow-Jones"는 1-gram으로 나누면 "Dow"와 "Jones"라는 의미 없는 단어가 되어버린다). 따라서 의미 있는 candidate term list를 만들기 위해, 크기가 \(n\)인 sliding window를 이용해서 1-gram부터 \(n\)-gram까지의 continuous하고 sequencial한 용어를 생성한다.
중요한 것은 문서 전체를 iterate하면서 \(<a>, <U>, <p> \)로 태깅되어 있는 단어들로만 candidate keyword set을 만든다는 것이다. 또, 다른 연구에서도 밝혀진 내용이지만, relevant한 키워드는 stopword로 시작하거나 끝나는 경우가 거의 없다고 한다. 따라서 n-gram을 만들 때 stopword로 시작하거나 끝나는 경우를 제외한다(대신 stopword가 중간에 들어가는 경우는 고려 대상에 포함한다 - philosophy of mind, language of thought).
키워드 제작 과정이 끝나면 각 candidate에게 점수가 주어진다. 이는 다음 알고리즘으로 묘사할 수 있다.

우선 각 candidate를 토큰으로 나누고, 이 토큰이 stopword인지 평가한다. non-stopword 토큰의 경우, 나머지 candidate 토큰의 \( S(t) \) 점수를 더하거나 곱할 때 자신의 \( S(t) \) 점수를 고려할 수 있게 한다(line 6~8). 반면, 해당 token이 stopword인 경우 특별 취급(?)을 해주게 된다. 가령 "language of thought"라는 candidate keyword를 생각해보자. 토큰으로 나누게 되면 "language", "of", "thought"가 각각 생성되며, "of"는 stopword에 속한다. 저자의 의도는 왼쪽("language") 및 오른쪽("thought") non-stopword 단어들의 \( S(t) \) 점수가 stopword의 \( S(t) \) 점수와 같은 맥락에 놓였을 때, 후자의 영향을 완화하는 것이다(너무 크니까). 이를 감안한 candidate keyword의 최종 점수는 밑의 식에 의해 주어진다.
$$ S(kw) = \frac{\prod _{t\in kw} S(t)}{KF(kw)*(1+\sum _{t\in kw} S(t))} $$
- \( kw \) : 하나 또는 그 이상의 term으로 이루어진 candidate keyword
2-5. Data deduplication and ranking
YAKE!는 최종 단계에서 candidate keyword 간 유사도 점수를 계산한 후, 이 유사도 점수가 \( \Theta \)보다 높은 candidate keywords를 제거한다. 유사한 candidate keyword를 비교하기 위해 keyword structure이라는 것이 만들어지는데, 이는 keyword가 모인 final list를 유지하는 것에 사용된다.
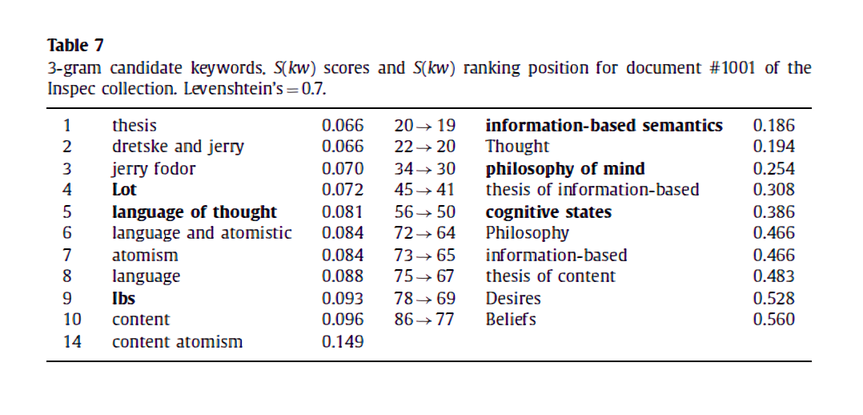
위와 같은 candidate keyword list가 있다고 해보자. 우선 이 중 가장 낮은 점수를 가진 thesis를 final list에 넣음으로써 structure을 초기화한다. 그 후 연속적인 candidate keyword("dretske and jerry")는 이미 structure 안에 있는 키워드와 비교되면서 유사도가 주어진 \( \Theta \)보다 높을 때마다 버려진다.
논문에서 유사도 점수를 계산하는 세 가지 method로 Levenshtein similarity, Jaro-Winkler similarity, 그리고 sequence matcher를 제시한다. 이 중에서도 주요하게 다뤄진 편집거리 알고리즘(Levenshtein similarity)은 문자열 A가 문자열 B와 같아지기 위해서는 몇 번의 연산을 진행해야 하는 지 계산함으로써 두 문자열이 얼마나 유사한 지를 알아낼 수 있는 알고리즘이다. 연산이라 함은 삽입(insertion), 삽입(deletion), 대체(replacement)를 말한다.
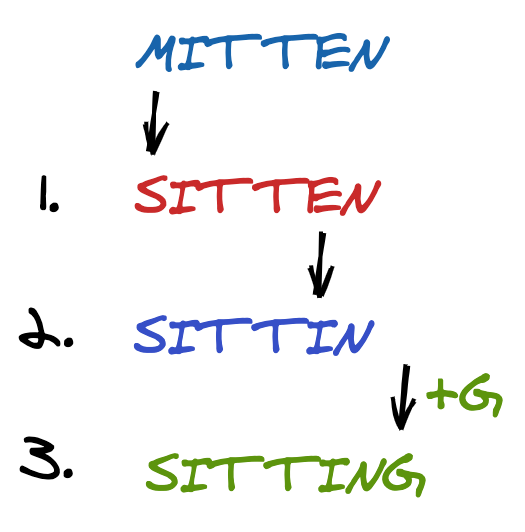
이렇게 candidate keyword list 안에서도 유사한 용어들을 제거함으로써 relevancy를 최대로 끌어올릴 수 있다!
다음 포스트에서는 직접 문서에 YAKE를 적용해 키워드를 추출하는 실습을 해볼 것이다.