[ML] CatBoost 소개 - Ordered Boosting, 범주형 피처 처리
우리는 이 포스트에서 LightGBM을 공부하면서 그래디언트 부스팅에 대해서도 알아봤다. 다시 소개하자면, 그래디언트 부스팅(gradient boosting)이란 경사하강법을 통해 가중치를 업데이트하면서 여러 개의 weak learner를 순차적으로 학습-예측하는 앙상블(ensemble) 학습 방식이다.
이번에 알아볼 CatBoost도 결정 트리에서의 그래디언트 부스팅 알고리즘을 기반으로 한다. Yandex 연구원들과 엔지니어가 개발했으며, 검색, 추천 시스템, 날씨 예측 등의 작업에 많이 사용된다. 2017년에 출판된 논문 CatBoost: unbiased boosting with categorical features을 참고하라.
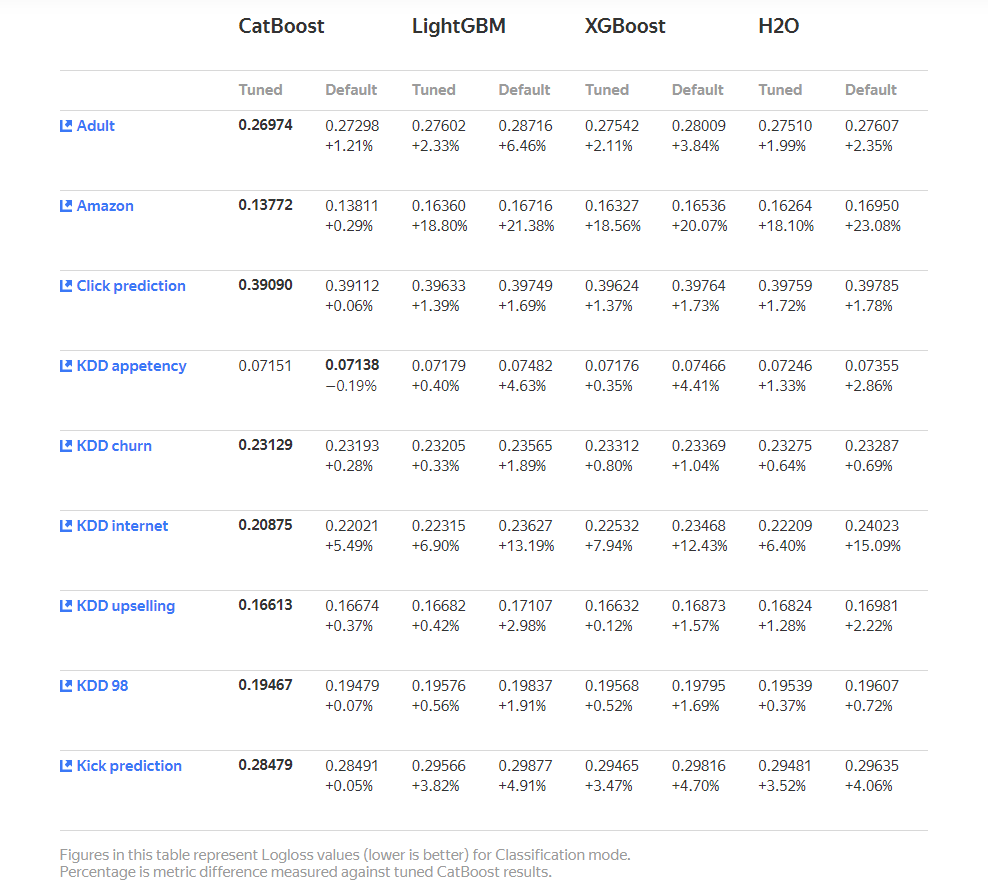
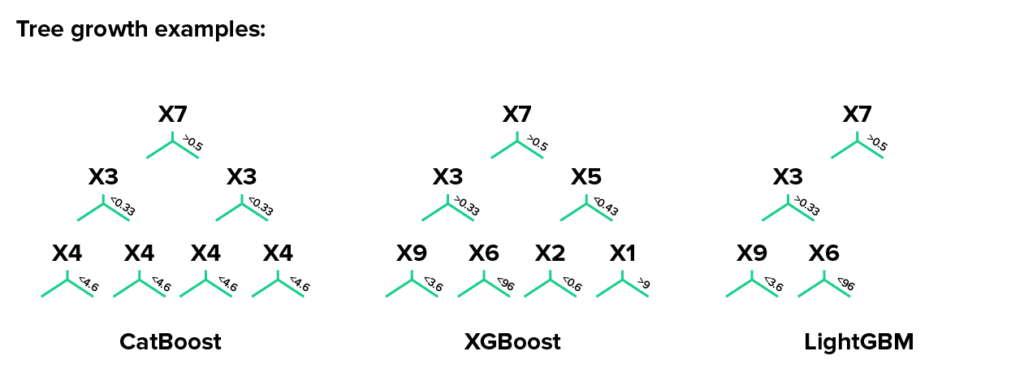
1. 장점
This paper presents the key algorithmic techniques behind CatBoost, a new gradient boosting toolkit. Their combination leads to CatBoost outperforming other publicly available boosting implementations in terms of quality on a variety of datasets. Two critical algorithmic advances introduced in CatBoost are the implementation of ordered boosting, a permutation-driven alternative to the classic algorithm, and an innovative algorithm for processing categorical features. Both techniques were created to fight a prediction shift caused by a special kind of target leakage present in all currently existing implementations of gradient boosting algorithms. In this paper, we provide a detailed analysis of this problem and demonstrate that proposed algorithms solve it effectively, leading to excellent empirical results.
- 출처 : CatBoost 논문 abstract
해당 논문이 다른 머신러닝 알고리즘보다 발전됐다고 자부하는 부분은 두 가지이다.
- 기존 알고리즘에 대한 순열 기반의 대안인 ordered boosting의 구현
- 범주형(categorical) 피처 처리를 위한 알고리즘 도입
두 기법 모두 현존하는 모든 그래디언트 부스팅 알고리즘 구현에 존재하는 특정한 종류의 target leakage로 인한 prediction shift를 해결하기 위해 만들어졌다. Prediction shift는 우리가 예측하고자 하는 변수(target이 되겠다)가 데이터셋에 있는 데이터에 가까워지고 실제 값과는 더 멀어질 때 발생한다. 왜냐하면 일반적인 GBM은 다음 스텝의 tree(혹은 모델) \( F^t \)를 만들 때, 현재 모델 \( F^{t-1} \)에서 쓰여진 데이터의 target value를 gradient estimate를 하는 데에 다시 쓰기 때문이다. 즉, 잔차 추정치가 변화되면서 overfitting에 취약해진다. 이를 어떻게 해결하는지 살펴보자.
Ordered Boosting
무한개의 훈련 데이터를 이용할 수 있다고 하면, 부스팅의 각 단계에서 독립적으로 새로운 데이터셋 \( D_t \)를 샘플링하고 현재 모델을 이 \( D_t \)들에 적용하여 변화되지 않는 잔차들을 얻을 수 있을 것이다. 하지만 현실적으로 레이블이 있는 데이터는 그 수가 제한되어있다. 우리는 모든 훈련 예제들에 대해 편향되지 않은 잔차들이 필요하다. 대신 모델 훈련에 사용된 예제들에 따라 다양한 모델 집합을 유지하는 것이 가능하므로, 잔차 없이 이 훈련된 모델의 집합을 사용하는 것이다. 이 모델의 집합을 구축하기 위해서 순서형 원칙(Ordering Principle)을 사용한다.

아이디어를 설명하기 위해, 훈련 예제 중 무작위 순열 \( \sigma \) 하나를 취한다고 가정하고, 모델 \( M_i \)와 같이 서로 다른 n개의 supporting 모델 \( M_1, M_2, ..., M_n \)를 유지한다. 이때 \( M_i \)는 순열의 처음 i 번째 예제만을 사용하여 학습된다. 각 단계에서 j 번째 표본의 잔차를 얻기 위해 모델 \( M_{j-1} \)을 사용한다(위 그림 참조). 이 결과를 Ordered Boosting 알고리즘이라고 한다.
불행하게도, 이 알고리즘은 복잡성과 기억력을 n배 증가시키는 n개의 다른 모델들의 훈련의 필요성 때문에 대부분의 실용적인 작업에서 실현 가능하지 않다. CatBoost에서는 기본 예측 변수(GBDT)로 결정트리를 사용하는 그래디언트 부스팅 알고리즘을 기반으로 이 알고리즘의 수정을 구현했다.
Categorical features
범주형 피처는 서로 비교가 불가능한 이산값의 집합(discrete set of values)이다. 이런 범주형 피처를 처리하는 가장 유명한 테크닉으로는 원-핫 인코딩이 있는데, 문제는 cardinality가 높으면 어마무시하게 많은 새로운 피처가 생긴다는 것이다. 이 문제를 해결하기 위해 범주를 제한된 수의 클러스터로 그룹화한 다음 원-핫 인코딩을 적용할 수 있다. 일반적인 방법은 각 범주의 기대 목표값을 추정하는 목표 통계량(TS)별로 범주를 그룹화하는 것이다. Micci-Carreca는 이 TS를 새로운 수치형 피처로 고려하는 방법을 제안하였고, 정보 손실을 최소화하는 선에서 범주형 피처를 다루는 가장 효율적인 방법으로 여겨졌다. 하지만 CatBoost에서는 위에서 설명했던 Ordering Principle을 gradient statistics에 적용하는 것이 더 낫다고 주장한다. 즉, Ordered TS를 사용하는 것이 더 효과적인 전략이라는 것이다. 자세한건 논문 속에...
CatBoost에서 Ordered TS를 사용해 범주형 피처를 처리하는 단계는 다음과 같다.
- 하나의 카테고리 피처(예: 국적)에서 시작한다. 이것을 \( x \)라고 하자.
- 무작위로 선택된 하나의 행(훈련 데이터셋에서 k번째 행)에서, 이 범주형 피처의 한 랜덤 레벨(i번째 수준의 \( x \))을 숫자(예: 네덜란드 by 5)와 교환한다.
- 이 숫자는 일반적으로 카테고리 수준에서 조건부인 목표 변수를 기반으로 한다. 즉, 이 target number은 expected 결과 변수를 기반으로 한다(????).
- 분할 속성(splitting attribute)은 두 세트의 훈련 데이터를 만드는 데에 사용된다: 모든 카테고리(예: 독일, 프랑스 등)를 가진 세트는 3단계에서 계산한 집합보다 큰 목표 변수를 가지며, 다른 세트는 더 작은 목표 변수를 갖는 집합이다.
3단계의 숫자는 그냥 랜덤한 숫자가 아니라, TS를 기반으로 한다. 보통 TS를 계산하는데는 Greedy, Holdout, Leave-out-one, 그리고 Ordered가 있고, CatBoost는 마지막 TS를 사용한다.
예제
Kaggle의 20201 TPS March 데이터에 어떻게 CatBoost를 이용했는지, 범주형 변수를 어떻게 처리했는지 기록이나 해야겠다. 데이터는 이쪽.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import RobustScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier
from sklearn.metrics import roc_auc_scoretrain = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
print("Size of total train dataset: {}".format(train.shape))
# Size of total train dataset: (300000, 32)
print("Size of total test dataset: {}".format(test.shape))
# Size of total test dataset: (200000, 31)
categoric_var = [col for col in train.columns if col.startswith('cat')]
numeric_var = [col for col in train.columns if col.startswith('cont')]
train_set, valid_set = train_test_split(train, test_size=0.2, stratify=train['target'], random_state=123)
print('PROPORTION OF TARGET IN THE ORIGINAL DATA')
print(train['target'].value_counts() / len(train))
print('PROPORTION OF TARGET IN THE TRAINING SET')
print(train_set['target'].value_counts() / len(train_set))
print('PROPORTION OF TARGET IN THE VALIDATION SET')
print(valid_set['target'].value_counts() / len(valid_set))
# PROPORTION OF TARGET IN THE ORIGINAL DATA
# 0 0.73513
# 1 0.26487
# Name: target, dtype: float64
# PROPORTION OF TARGET IN THE TRAINING SET
# 0 0.735129
# 1 0.264871
# Name: target, dtype: float64
# PROPORTION OF TARGET IN THE VALIDATION SET
# 0 0.735133
# 1 0.264867
# Name: target, dtype: float64
y_train = train_set['target']
train_set.drop(['id', 'target'], axis=1, inplace=True)
y_valid = valid_set['target']
valid_set.drop(['id', 'target'], axis=1, inplace=True)
rs = RobustScaler()
rs.fit_transform(train_set[numeric_var])
rs.transform(valid_set[numeric_var])clf_catboost = CatBoostClassifier(iterations=100, random_state=123)
clf_catboost.fit(train_set, y_train,
cat_features=np.where(train_set.dtypes != np.float)[0],
eval_set=(valid_set, y_valid))
fit 함수로 학습시킬 때 범주형 피처를 처리할 수 있도록 하는 하이퍼 파라미터가 cat_features이다.
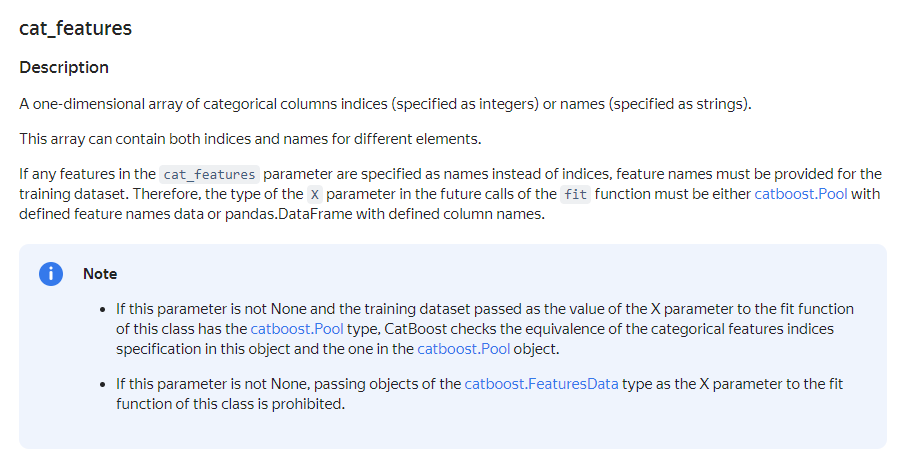
categorical columns indices, 즉 범주형 피처의 열 인덱스(정수) 혹은 이름(문자열)을 넣어주면 된다. 필자는 위에 np.where()로 인덱스로 변환해서 넣어주었다. 참고로 default는 None이다.
cb_auc = roc_auc_score(y_valid, clf_catboost.predict_proba(valid_set)[:,1])
print("AUC score of CatBoost: {:.3f}".format(cb_auc))
# AUC score of CatBoost: 0.889
참고자료: https://medium.com/whats-your-data/working-with-categorical-data-catboost-8b5e11267a37