[ML] 앙상블(Ensemble Learning) - Voting, Bagging, Boosting
포스트 순서가 역순으로 거슬러 올라가는 것 같지만ㅜㅠ 여러 분류기들을 다루는 김에 앙상블의 종류에 대해 정리해보려고 한다.
앙상블 학습(ensemble learning)이란 무엇인가? 여러 개의 '약한 모델'(보통 weak learner라고 통칭한다)을 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법이다. 어떤 모델을 어떻게 쌓느냐에 따라 통상적으로 세 가지 방법으로 나뉜다.
Voting 방식
서로 다른 알고리즘을 가진 모델을 병렬로 결합한다. 최종 output이 continuous value이면(회귀) 각 모델의 예측값을 더해 평균을 냄으로써 앙상블 모델의 출력을 얻을 수 있다. 반면 최종 output이 class label이면(분류) 다음과 같은 두 방식 중 하나를 선택해서 결과값을 도출한다.
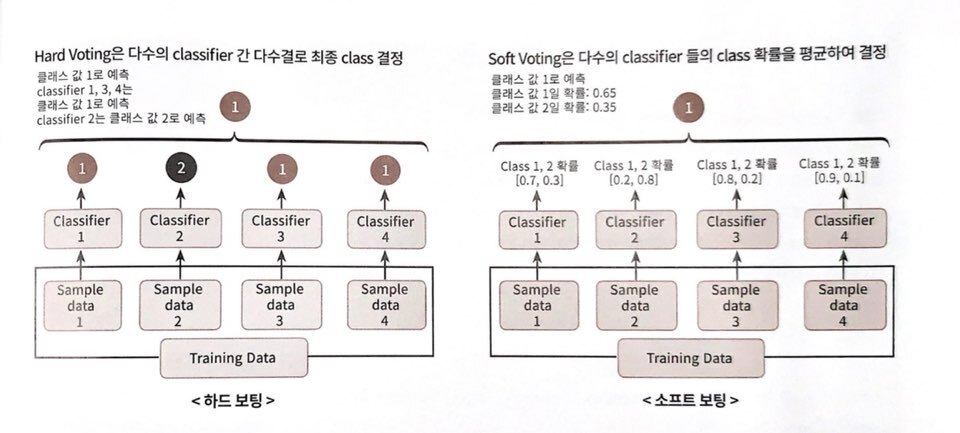
- Hard Voting: 예측한 결과값들 중 다수의 모델이 결정한 예측값을 최종 voting 결과값으로 선정 (다수결 원칙) $$ Ensemble(\hat{y}) = argmax(\sum_{j=1}^n I(\hat{y_j}=i)), i\in (0,1) $$
- Soft Voting: 모델들의 레이블 값 결정 확률을 모두 더하고, 이를 평균내서 이들 중 확률이 가장 높은 레이블 값을 최종 voting 결과값으로 선정 $$ Ensemble(\hat{y}) = argmax(\frac{1}{n}\sum_{j=1}^n P(y=i)), i\in (0,1) $$
Bagging 방식
같은 알고리즘으로 여러 개의 모델을 병렬적으로 만들어서 투표를 통해 최종 결정한다. Voting 방식과의 공통점은 여러 개의 모델이 투표를 통해 결과를 예측한다는 것이고, 차이점은 Voting은 서로 다른 알고리즘의 모델을 사용한다는 것이다.
대표적으로 랜덤포레스트(random forest) 알고리즘이 있다. 랜덤포레스트는 결정트리를 기반으로 함으로써 빠른 수행 속도가 장점이다.
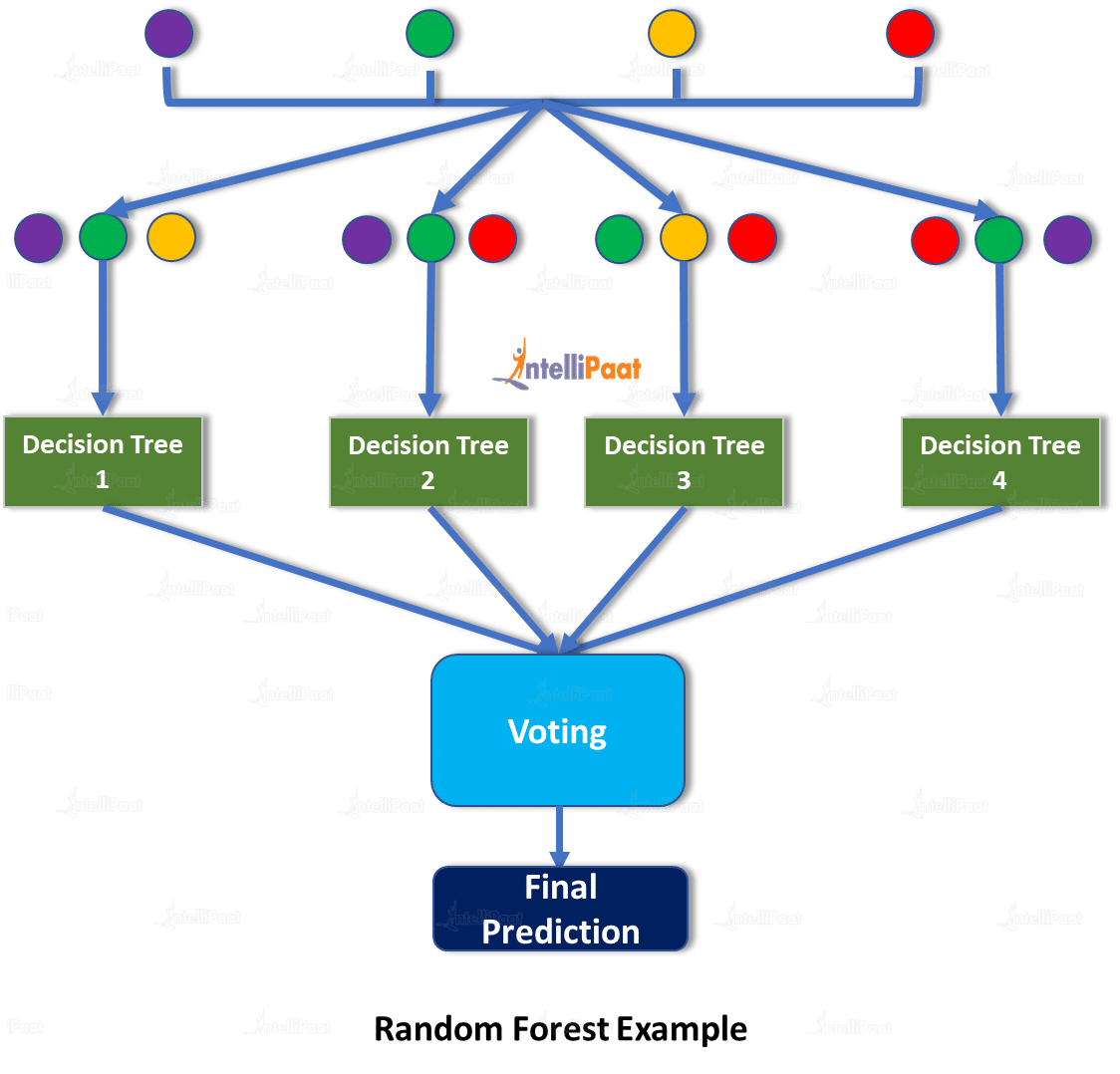
위 그림을 보면, 분류기가 전부 결정트리인 것을 확인할 수 있다(같은 알고리즘의 weak learners 사용). 또, 전체 학습 데이터셋을 데이터 샘플링(data sampling)을 통해 각각 다른 데이터셋인 subset #보라, #초록, #노랑, #빨강으로 나눈다. 이 subset들은 크기가 동일하고 어느정도 중첩되게 샘플링이 되는데, 이를 부트스트랩 결합(boostrap aggregation; 보통 그냥 부트스트랩이라고 한다)이라고 한다. 마지막 보팅 단계에서는 soft voting을 통해 최종 예측값을 결정한다.
Bootstrap
부트스트랩이란 단순 복원 임의추출법을 통해 raw data로부터 같은 크기의 표본 자료들을 생성하는 것을 말한다.
왜 이렇게 하는가? 첫번째는 분류 또는 회귀에 상관없이, 훈련된 데이터셋의 이론적인 분산 때문이다. 우리가 가지고 있는 데이터셋은 실제 알려지지 않은 모집단에서 나온 관측개체임을 상기해보자. 다시 말하면 데이터를 수집했던 확률변수의 정확한 분포를 모른다는 것이므로, 측정된 통계치의 신뢰도를 가늠할 방법이 없다. 그래서 부트스트랩핑을 통해 측정된 n개의 데이터 중에서 중복을 허용하여 m개를 뽑고, 그들의 평균을 여러 번 구함으로써 평균의 분포를 구한다. 이를 통해 앙상블 모델의 각 components보다 분산을 줄일 수 있다. 두번째는 데이터셋 내의 데이터 분포가 고르지 않은 경우를 들 수 있다. 가령 콜라와 사이다를 구분하는 분류기를 학습한다고 할 때, 데이터셋 내에 콜라 이미지가 1장만 있다고 해보자. 이러면 데이터 분포의 불균형성(imbalance dataset) 때문에 분류기가 콜라의 특징을 제대로 파악할 수가 없다. 이를 해결하기 위해 여러 가지 방법이 있는데 그 중 하나가 부트스트랩핑을 통해 콜라 데이터 수를 늘리는 것이다. 왜냐하면 부트스트랩을 수행하면 '크기가 동일하게' 중복 샘플링 되게 때문이다.
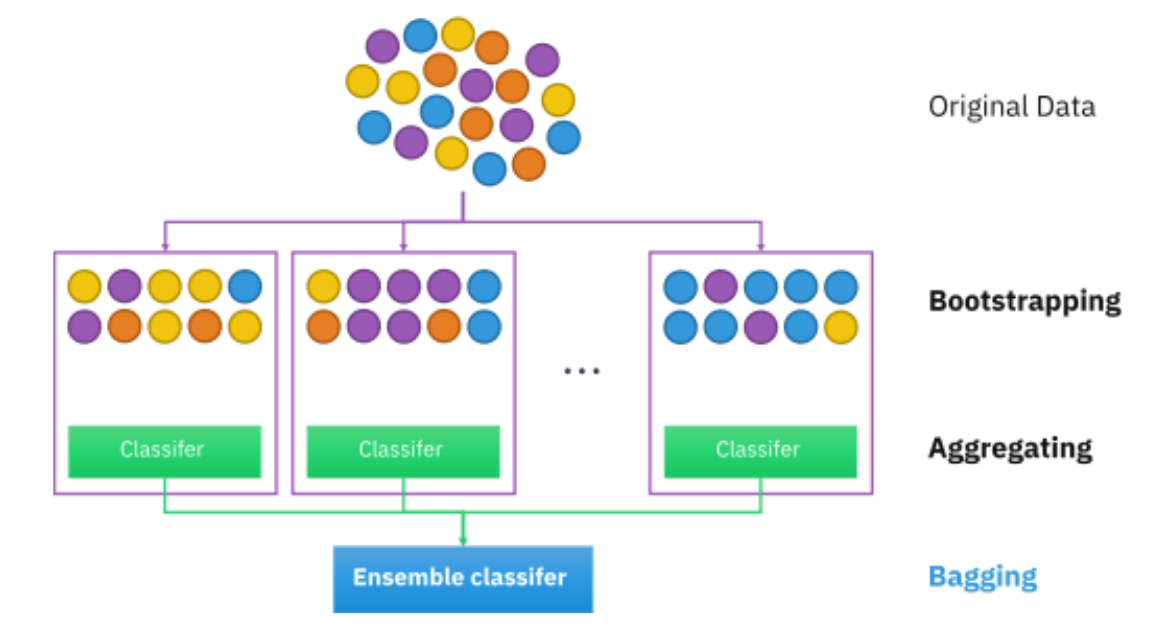
즉, bagging 방식은 이 부트스트랩핑 덕분에 high variance 모델의 variance를 낮추는 데에 효과적이다. 분산과 편향에 대해 다시 설명하고 가자면,
- 편향은 학습 알고리즘에서 잘못된 가정을 했을 때 발생하는 오차이다. 높은 편향값은 알고리즘이 데이터의 특징과 결과물과의 적절한 관계를 놓치게 만드는 과소적합(underfitting) 문제를 발생 시킨다.
- 분산은 학습 데이터셋에 내재된 작은 변동(fluctuation) 때문에 발생하는 오차이다. 높은 분산값은 큰 노이즈까지 모델링에 포함시키는 과대적합(overfitting) 문제를 발생시킨다.
대락적으로 말해서, 부트스트랩 샘플이 거의 독립적이고 동일한 분포(i.i.d)이기 때문에 학습된 기본 모델도 마찬가지가 된다. 그런 다음 이 기본 모델들의 예측값을 평균화하는 것은 최종 output을 변화시키지 않고 분산을 감소시키게 된다(just like averaging i.i.d. random variables preserve expected value but reduce variance). 부트스트랩으로 분산을 줄이는 과정을 설명해보자.
- 여러 부트스트랩 샘플을 생성함으로써 각각의 새로운 부트스트랩 샘플이 실제 분포에서 도출된 또 다른 (거의) 독립적인 데이터 집합으로 작용하도록 한다.
- 그 다음 이러한 각 표본에 대한 weak learner를 적합시키고 결과를 평균낼 수 있도록 집계한다. 이렇게 하면 따로따로 있는 분류기보다 분산이 적은 앙상블 모델을 얻을 수 있다.
Boosting 방식
LightGBM 포스트에서 이미 설명했지만 다시 한 번 하겠다... Boosting 앙상블 학습은 여러 개의 약한 학습기를 순차적으로 학습-예측해나가면서, 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해나가는 방식이다. 여기서 중요한 점은 직렬 학습이라는 것이다. 위의 Voting이나 Bagging은 모두 병렬 학습이지만 Boosting에는 순서가 있다.

위의 그림처럼 모델 1이 예측하고 남은 잔차들을 모델 2, 모델 3를 차례로 지나가면서 줄여가는 것 Boosting 알고리즘이다. 따라서 높은 bias를 개선해나가는데 효과적이다. 위에서 편향은 '잘못된 가정을 했을 때 발생하는 오차'라고 말했다. 모델 1이 예측해서 남은 오차를 다음 모델이, 또 다음 모델이 계속 줄여나감으로써 편향값이 낮아진다고 할 수 있다!
Boosting 알고리즘을 사용하는 대표적인 모델로 AdaBoost와 GBM이 있다.
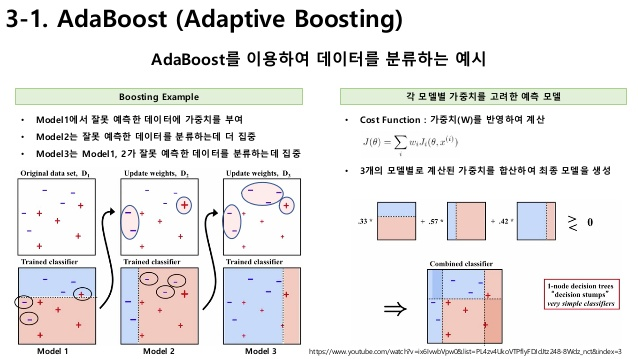
AdaBoost는 이상치(outlier)에 각각 가중치를 부여한 다음, 마지막에 모두 결합해서 결과를 예측한다. 반면 GBM(gradient boosting machine)은 AdaBoost와 원리는 같으나, 가중치 업데이트에 경사하강법을 이용한다는 점에서 차이가 있다. 자세한 건 LightGBM 포스트를 참고.