[ML] 손실함수와 경사하강법 - Loss function & Gradient Descent
1. 손실함수 (Loss Function)
데이터 분석을 위한 수학 모델은 파라미터가 중요한 역할을 한다. 신경망에서는 가중치(weight)와 편향(bias)이 파라미터 역할을 담당한다. 이 파라미터에 현실의 데이터(신경망에서의 학습 데이터)를 적용하면 모델을 확정할 수 있다. 이를 수학에서는 '최적화', 신경망에서는 '학습'이라고 한다.
그렇다면 파라미터를 어떻게 결정할 수 있을까? 예측값과 실제값 사이의 오차가 모든 데이터를 대상으로 최소가 되도록 결정하면 된다. 손실함수란 모델의 파라미터를 이용하여 표현한 오차 전체의 함수이고, 우리는 손실함수가 최소가 되는 지점을 찾으면 된다. 손실함수는 비용함수(cost function), 목적함수(objective function), 오차함수(error function) 등으로도 부른다.
MSE
단순회귀분석으로 예를 들어보자. 종속변수 Y와 독립변수 X가 존재할 때, 회귀 방정식은
$$ y = px + q $$
로 표현할 수 있다. k번째 관측개체의 값을 각각 \( x_k, y_k \)라고 하면 k번째 관측개체의 실제값 y_k와 회귀분석에서 얻을 수 있는 예측값 \( px_k + q \), 오차 \( e_k \)는 다음과 같이 나타낸다.
$$ e_k = y_k - (px_k+q) $$
이 포스트에서도 볼 수 있지만, 자료 전체의 오차를 정의하는 방법은 다양하다. 그중 가장 간단하면서 표준으로 여기는 것으로 제곱오차의 총합(MSE)이 있다. 즉, 회귀분석에서 손실함수 \( C \)는
$$ C = \frac{1}{n}\sum_{k=1}^n (y_k - (px_k+q))^2 $$
Cross-Entropy
신경망에서 수학 모델을 정하는 파라미터는 앞서 말했듯 가중치와 편향이다. 이 파라미터 역시 회귀분석과 수학적으로 동일하게 결정된다. 즉, 신경망에서 얻을 수 있는 손실함수 \( C \)가 최솟값이 되도록 가중치와 편향이 결정되고, 우리는 이러한 과정을 '최적화한다'고 한다.
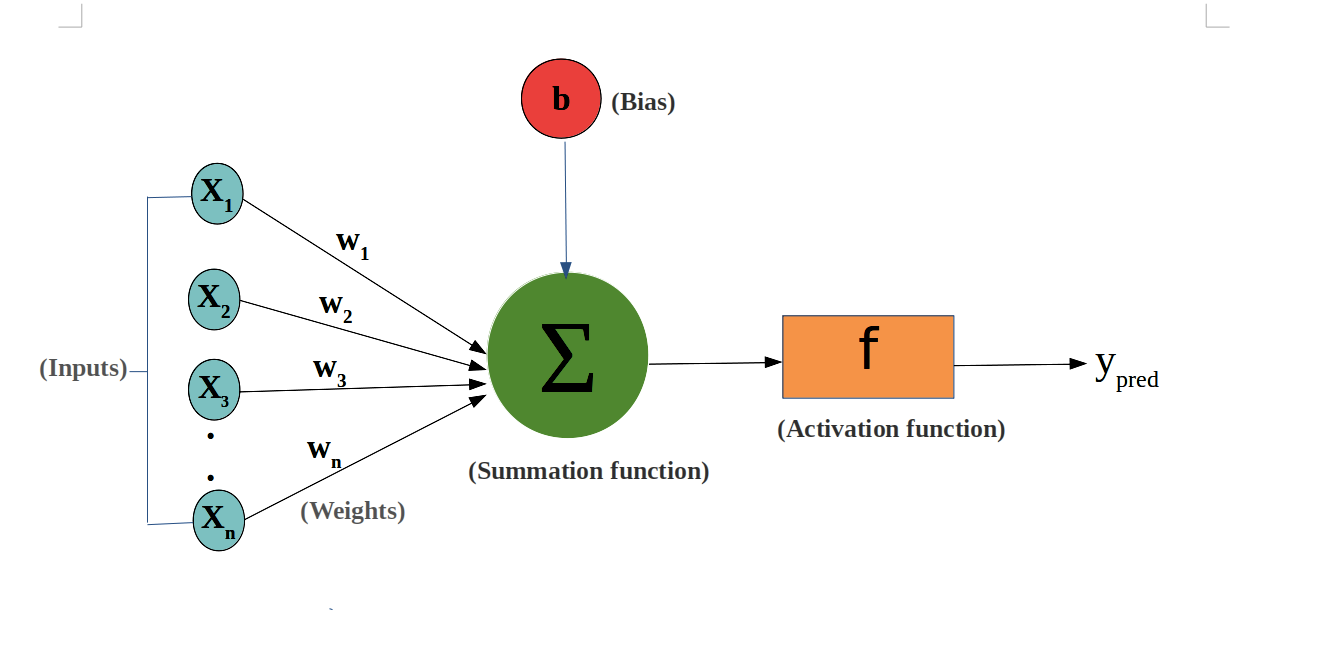
작동원리는 같기 때문에 신경망 학습에서도 제곱오차를 쓸 수 있다. 하지만 회귀분석보다 복잡하기 때문에 실제 계산 시간이 너무 오래 걸린다. 이러한 단점을 극복하는 다양한 오차 지표가 제안되고 있는데, 그중 유명한 것이 교차 엔트로피(cross entropy)이다.
예를 들어 0 혹은 1의 필기체 숫자를 식별하는 신경망이 있다고 하자(Binary classification)
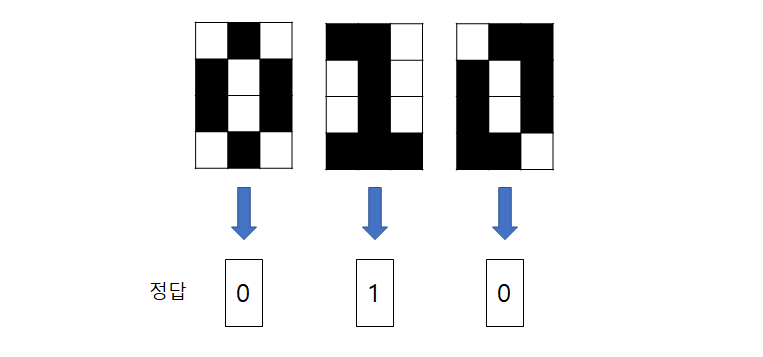
신경망의 예측값은 출력층에 있는 유닛의 출력 변수로 나타낸다.
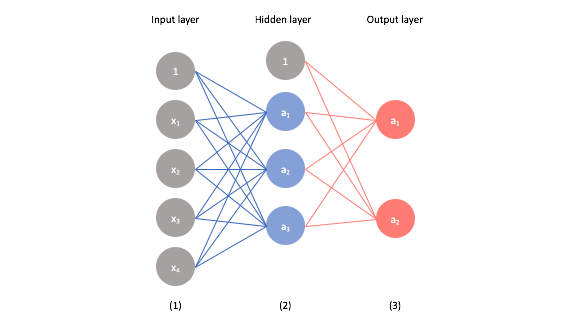
출력층 첫 번째 유닛을 \( a_1^3 \)이라 하고 두 번째 유닛을 \( a_2^3 \)이라고 하면, \( a_1^3 \)는 필기체 숫자 0에, \( a_2^3 \)는 필기체 숫자 1에 강하게 반응한다. 또, 두 유닛은 활성화 함수로 시그모이드 함수를 사용할 때 다음의 값을 가질 것으로 예측하는 변수이다.

다시 저 위에 숫자가 적혀있는 이미지를 보자(학습 데이터). 우리는 육안으로 0, 1, 0인 것을 판단할 수 있지만, 신경망이 막 계산을 시작했을 때는 이미지가 어떤 숫자인지 판단할 수 없다. 그래서 주어진 이미지의 숫자가 무엇인지 신경망에 가르칠 필요가 있다. 즉, 출력층의 두 유닛에 정답이 되는 두 변수 \( t_1, t_2 \)를 제공한다.

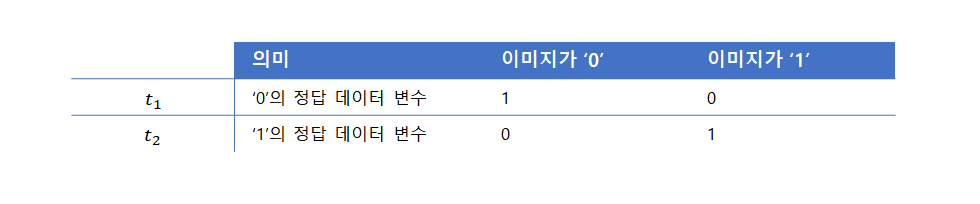
이제 신경망에서의 손실함수 \( C \)를 다음과 같이 표현할 수 있다.
$$ C = -\frac{1}{n}\sum_{k=1}^n (t_k loga_k + (1-t_k)log(1-a_k)) $$
2. 경사하강법 (Gradient Descent)
지금까지 MSE와 Cross-entropy loss function에 대해 알아봤다. 이제 파라미터를 결정하기 위해서는 손실함수를 최소화해야 한다. 경사하강법은 이 '어떻게 최소화 할 것인가?'와 연관되는 방법이다. 예를 들어 함수 \( z = f(x, y) \)가 있을 때 함수 z를 최소화하는 x, y는 어떻게 구하면 좋을까? 함수 z를 최소화하는 x, y가 다음의 관계를 만족시킨다는 사실을 이용하는 것이다.
\( \frac{\partial f(x,y)}{\partial x} = 0, \frac{\partial f(x,y)}{\partial y} = 0 \)
회귀분석에서의 손실함수를 revisit해보자. MSE 손실함수를 위의 관계처럼 편미분해보자. 그러면 파라미터 p와 q는 다음과 같이 구할 수 있다.
$$ \frac{\partial C}{\partial p} = 0, \frac{\partial C}{\partial q} = 0 $$
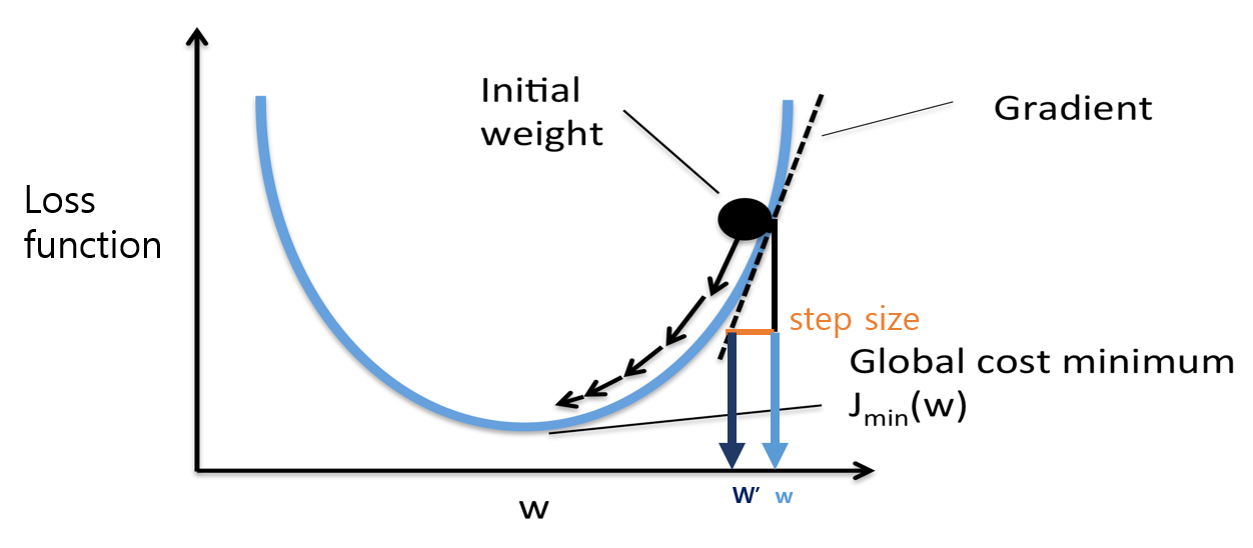
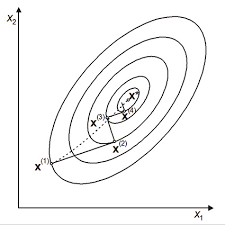
근데 대부분의 경우 이 식이 한 번에 쉽게 풀리지는 않는다. 특히 신경망에서 유닛 수가 늘어나면 어마어마한 개수의 파라미터가 나온다. 차선의 방책으로 우리는 그래프 상의 점을 조금씩 움직여 함수의 최솟값인 점을 찾는다. 이것이 경사하강법의 기본 원리이다.
미분 가능한 함수 \( f(x_1, x_2,..., x_n) \)에서 변수를 차례로 \( x_1 + \Delta x_1, x_2 + \Delta x_2, ..., x_n + \Delta x_n \)로 작은 값으로 변화시켰을 때, 함수 f가 최솟값이려면 다음 함수가 성립한다.
$$ (\Delta x_1, \Delta x_2,..., \Delta x_n) = -\eta\left ( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n}\right ) $$
- \( \eta \)는 학습률(learning rate)로, 작은 값을 갖는 양의 상수임
위 식을 이용하면 컴퓨티에서 \( C \)가 최솟값이 되는 가중치(w) 및 편향(b)을 계산할 수 있다. 예를 들어 현재 변수의 위치\( (w_{11}^2, ..., w_{11}^3,..., b_1^2,...,b_1^3) \)에 식의 좌변에서 구한 변위 벡터를 더해 새로운 위치를 구하면 \( (w_{11}^2+\Delta w_{11}^2, ..., w_{11}^3+\Delta w_{11}^3,..., b_1^2+\Delta b_1^2,...,b_1^3+\Delta b_1^3) \)이다. 이 위치에서 다시 위 식의 계산을 반복해서 최솟값이 되는 가중치와 편향을 계산한다.