[DL] keyword extraction with KeyBERT - 개요 및 알고리즘
키워드 추출(keyword extraction)은 원본 문서를 가장 잘 나타내는 중요한 용어(word 단위) 또는 구문(phrase 단위)을 찾아내는 작업이다. 좋은 키워드를 식별하는 것은 문서의 내용을 정확히 기술하는 데 중요할 뿐만 아니라, 키워드를 메타 데이터로 저장함으로써 보다 빠른 정보 검색을 가능하게 할 수 있다. 이번 포스트에서는 키워드 추출의 여러가지 방법들 중 state-of-art 기술이라 불리는 BERT를 이용한 KeyBERT 모델을 소개해보겠다.
논문은 아직 나온게 없고 깃헙 페이지와 소스코드가 오픈되어있다. 튜토리얼 위주이지만 관련된 미디엄 포스트도 존재. 이분... BERTopic도 만드셨던데 여러모로 도움 많이 받는 중이다^^..
본문은 깃헙 페이지에 소개되어있는 알고리즘 설명 위주로 작성되었다.
1. General flow
KeyBERT는 텍스트 임베딩을 형성하는 단계에서 BERT를 사용하기 때문에 BERT-based solution이라 불린다.
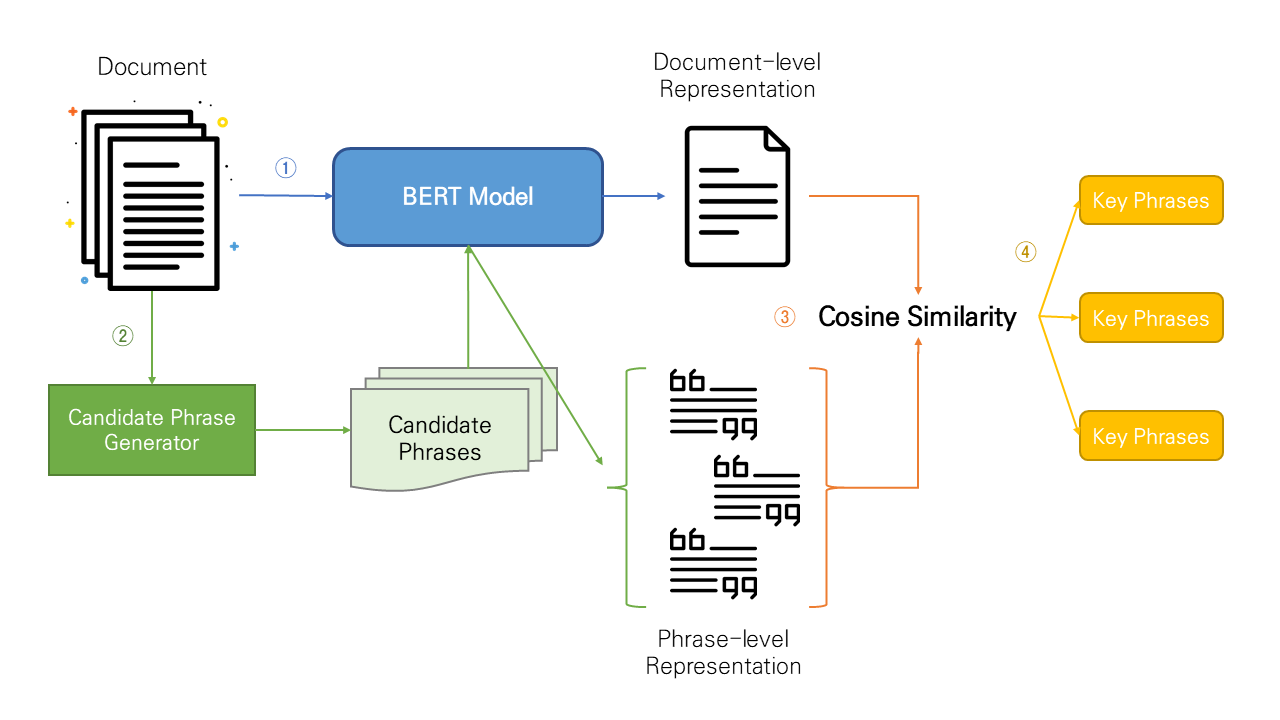
KeyBERT는 크게 4단계를 거쳐 문서에서 key word/phrase set을 뽑아낸다.
1. Document-level representation (by document embeddings extracted with BERT)
2. Phrase-level representation (by word embeddings extracted for N-gram words/phrases and BERT)
3. Use of cosine similarity to find the words/phrases that are most similar to the document
- (optional) MMR or Max Sum Similarity
4. Extraction of words/phrases that best describe the entire document
2. Algorithm
2-1. Generate candidate words/phrases
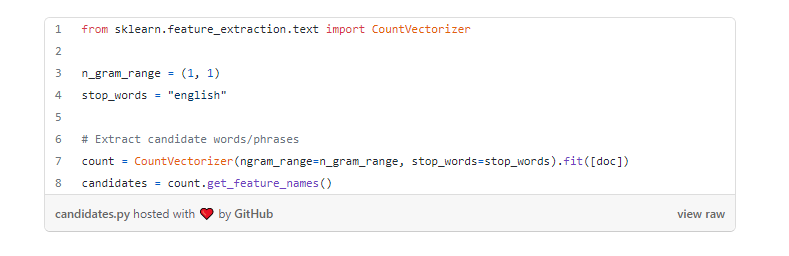
공식 튜토리얼에서는 N-gram 모델을 사용해 문서의 각 문장을 단어로 쪼개준다(하이퍼파라미터로, 조정 가능). 물론 KeyBERT 내장 라이브러리만 쓸 수 있는 것은 아니고 sklearn의 CountVectorizer을 써서 쪼갤 수도 있다. 문서와 마찬가지로 쪼갠 이후 BERT를 통해 각 단어에 대한 임베딩 벡터를 추출한다.

2-2. Embedding models
KeyBERT 오브젝트를 만들면서 임베딩 모델을 지정해줄 수 있다(default sentence embeddings model as "all-MiniLM-L6-v2" from sentence-transformers). 다음과 같은 임베딩 모델 라이브러리를 지원한다.
- Sentence-Transformers
- Flair
- Spacy
- Gensim
- USE
여기에서 각 모델에 대한 정보를 확인해볼 수 있다. BERT 임베딩은 document에 대해서, 그리고 이전 단계에서 쪼개져 나온 candidates에 대해 각각 수행된다.
2-3. Calculating similarites between document embedding - word/phrase embeddings
문서와 가장 유사한 key words/phrases를 찾는 단계이다. 문서와 가장 유사한 candidate는 문서를 나타나기 위한 적절한 키워드라고 간주하는 것이다. candidate keywords/phrases와 문서의 유사도를 계산하기 위해 벡터들 사이의 코사인 유사도를 사용한다(cosine similarity between document-level representation and phrase-level representations).
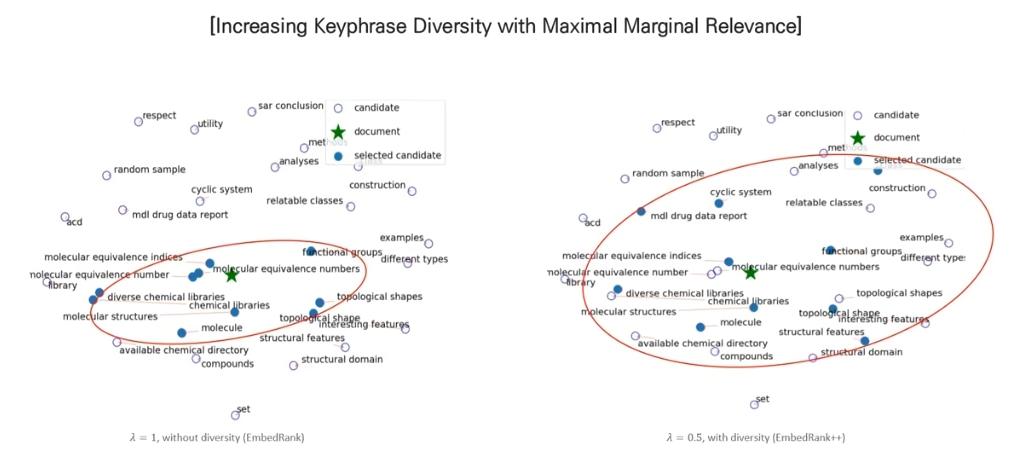
벡터 간 거리를 이용한 단순한 접근방식이지만 결과가 그다지 좋지 않아보일 때도 많다(ex. 중복된 의미의 키워드가 너무 많음). 키워드의 diversity를 극대화하기 위해 아래와 같은 두 가지 diversification method를 추가할 수 있다.

MMR (Maximal Marginal Relevance)
- 참고자료: https://www.youtube.com/watch?v=2UkMBtE2UpI
EmbedRank라는 키워드 추출 알고리즘에서 소개한 MMR 기법을 사용한다. MMR이란 검색 엔진 내에서 본문 검색(text retrieval) 관련하여 검색(query)에 따른 결과(document)의 다양성과 연관성을 control하는 방법론이다. EmbedRank의 original 계산식은 다음과 같다.
$$ MMR := argmax_{D_i\in R \setminus S}[\lambda\cdot Sim_1(D_i,Q) - (1-\lambda)\: \underset{D_j\in S}\max Sim_2(D_i, D_j)] $$
- \(D_i \): Documents in the collection
- \( Q \): Query
- \( R \): Relevant documents in \( C\)
- \( S \): current result set
- \( R\in S \): Set of unselected documents in \(R\)
여기서 중요한 것은 하이퍼파라미터 \( \lambda \)인데, \( \lambda\)를 조정하면서 diversity의 정도를 조절할 수 있다.
(Higher \( \lambda\): Higher accuracy, Lower \( \lambda \): Higher diversity) - 람다가 클수록 검색값과 좀 더 연관성이 높은 결과, 작을수록 다양성 강조

S에 모든 원소가 추가될 때까지 iteration을 반복하면 다양성이 추가된 요소의 우선순위를 구할 수 있게 된다.
실제 EmbedRank에서 MMR을 적용할 때는 아래의 식과 같이 변형된 코사인 유사도 값을 이용하게 된다.
$$ MMR := argmax_{C_i\in C \setminus K}[\underbrace{\lambda\cdot \widetilde{COS}(C_i,doc)}_A - \underbrace{(1-\lambda) \underset{C_j\in K}\max{}\widetilde{COS}(C_i, C_j)}_B] $$

- \( C\): Set of candidate keyphrases
- \( K \): Set of extracted keyphrases
- \( doc \): Full document embedding
- \( C_i, C_j \): Embeddings of candidate phrases \( i, j\)
식에서 A파트는 문서와 가장 유사한 key pharse 찾기 위함이고, B파트는 이미 선택된 phrase와는 공통된 의미를 최소한으로 공유하기 위한 것으로 해석할 수 있다.
Max Sum Similarity
The maximum sum distance between pairs of data is defined as the pairs of data for which the distance between them is maximized. In our case, we want to maximize the candidate similarity to the document whilst minimizing the similarity between candidates.
candidate-document 간 거리는 최소로 하면서 candidate-candidate 간 거리는 최대로 함으로써 의미적으로 풍부한 키워드 set을 얻는다. 문서와 가장 유사한 words/phrases 2개를 사용해 이 두개의 top_n 단어에서 모든 top_n combination을 취해 코사인 유사도를 구한다. 여기서 유사도가 가장 낮은(least similar) 조합을 추출한다.