[DL] CUDA, cuDNN이란? - layered architecture for Deep Learning
딥러닝을 공부하는 사람이라면 한 번씩 마주했을 에러들이 있다.
RuntimeError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 6.00 GiB total capacity; 2.02 GiB already allocated; 25.70 MiB free; 2.05 GiB reserved in total by PyTorch)
OOM 메모리 할당 에러... 아니면 이런거
RuntimeError: CUDA error: device-side assert triggered
요는, tensorflow든 pytorch든 서로 다른 프레임워크를 사용해도 특정 문제에 대해 리턴되는 CUDA 에러는 같다는 것이다. 이는 CUDA가 딥러닝 프레임워크나 어플리케이션 단에서 사용하는 프로그래밍 언어와는 독립적으로 존재한다는 사실을 방증하는데, 이번 포스트에서는 CUDA와 cuDNN이 무엇이고, 딥러닝의 layered architecture 안에서 어떤 역할을 하는지에 대한 포스트를 작성해보려 한다.
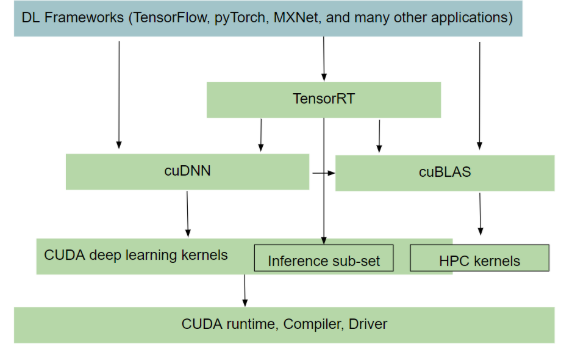
0. Prerequisites
CPU vs GPU
CPU(Central Processing Unit; 중앙 처리 장치)는 범용 프로세서로, 직렬 작업, 연산 작업 및 파일 작업에 최적화되어 있다. 거의 모든 데스크탑이나 노트북에는 여러 개의 코어(core)가 있는 CPU가 내장되어 있는데, 코어가 많을 수록 CPU의 성능이 높아진다. (예전에는 클럭 속도나 IPC 등의 요소도 고려가 많이 되었지만, 하드웨어적인 limitation에 도달했다고 함 - 4GHz의 벽)
CPU를 이용한 연산은 multi-processing, multi-threading 등을 이용하여 CPU가 보유한 코어 갯수만큼을 이용해 수행할 수 있다. 기존의 컴퓨터 연산은 RAM에 기록된 데이터를 불러와 CPU에서 연산 처리하였는데, 이당시 게임용이나 사무용 데스크탑에 쓰이는 CPU 코어의 평균 개수는 4개였다 - 현재 필자가 쓰는 데스크탑 CPU는 8코어이다.

반면, GPU(Graphics Processing Unit; 그래픽 장치)는 SIMD(Single Instruction Multiple Data ; 대규모 병렬 컴퓨팅) 연산을 수행하도록 최적화된 특수 목적 프로세서이다. 왜 'Graphic Processing' 장치라고 하냐고 하면, GPU의 개발 자체는 게임 산업의 3D 그래픽 요구 사항에 의해 주도되었기 때문이다. 여기서 생각해볼 점은, 3D 그래픽을 생성하기 위해 최적화된 연산(선형 대수의 행렬 연산 같은)이 계산 비용이 많이 드는 과학 문제에 필요한 계산 유형이라는 것이기도 한다는 것이다. NVIDIA가 1999년 3D geometry 연산과 조명 연산을 그래픽 장치에서 하드웨어적으로 처리할 수 있도록 한 GeForce 256을 출시하면서, 우리가 지금 생각하는 GPU에 가까워지는 데에 이러한 생각이 반영되었다고 볼 수 있다.
어쨋든 GPU가 CPU에 비해 가진 압도적인 장점은 코어 갯수에 있다. 일반적인 CPU가 1개에서 8개 정도의 코어를 갖는 것에 비해 GPU는 보통 수 백개에서 수 천개의 코어를 갖는다 - 현재 필자가 쓰는 데스크탑의 GPU는 10,496코어이다^^ . 각각의 코어 별 속도는 CPU가 훨씬 빠르긴 하지만, GPU는 압도적인 코어 갯수로 many-core dependent한 연산을 진행한다. 이것이 단순한 연산의 병렬 처리가 많은 그래픽 및 머신 러닝 task에 GPU 사양이 중요한 이유이다.
1. What is CUDA?
2006년 11월, NVIDIA는 Computed Unified Device Architecture, CUDA를 발표한다. CUDA는 NVIDIA GPU의 병렬 컴퓨팅 엔진을 활용하여 CPU보다 더 효율적인 방법으로 많은 복잡한 계산 문제를 해결하는, 병렬 컴퓨팅 플랫폼 및 프로그래밍 모델이다 (a general purpose parallel computing platform and programming model).

우리가 언어를 매개로 의사소통을 하듯이 기계와 커뮤니케이션을 하기 위해서는 프로그래밍 언어가 필요합니다. 개발자들이 프로그래밍 언어로 컴퓨터에 지시를 내리면, 지시문을 명령어로 번역, 컴퓨터가 효과적으로 수행할 수 있도록 하는 것을 바로 컴파일러(compiler)라고 하는데요. GPU 컴퓨팅에도 일종의 컴파일러 역할을 수행하는 도구가 있습니다. 바로 CUDA(Computed Unified Device Architecture)입니다.
- 출처 : NVIDIA 블로그 (https://blogs.nvidia.co.kr/2018/01/16/cuda-toolkit/)
CUDA를 사용하면 전체 코드 중 실행 시간의 90% 내외를 잡아먹는 일부의 코드, 즉 bottleneck을 가져와 병렬 버전으로 변환한 다음 GPU에서 실행 속도를 높일 수 있다. CPU는 코어의 대부분을 스칼라 연산 작업에 할당하는데, 한 번에 하나의 데이터(예: \(r1+r2=r3\))에 대해 연산을 수행한다는 것을 의미한다. 이는 1단계 계산 결과에 따라 2단계에서 수행할 작업이 결정될 때는 효율적이지만, 많은 데이터에 대해 동일한 작업을 수행해야 될 때는 비효율적이다. 반면 GPU는 코어의 대부분을 SIMD 아키텍처에 할당한다. 예를 들면 \([a0, a1, a2, a3, ...]+[b0, b1, b2, b3, ...] = [a0+b0, a1+b1, a2+b2, a3+b3, ...]\)와 같이 벡터 데이터의 배열에 대한 작업을 수행하는 것인데, 데이터셋에 대해 동일한 일련의 작업을 수행해야 하는 경우 스트림에 스케줄링 된다. GPU는 stream processor에 배열된 SIMD 연산을 수행하기 위한 수백 개의 구조를 포함한다. 이를 통해 많은 데이터를 병렬로 조작하는 것이다. loop 계산은 특히 수학이나 화학, 물리학 응용 분야에서 많이 수행되기 때문에 CUDA를 사용한 GPU 병렬 계산이 딥러닝에서도 효과적일 수밖에 없다.

CUDA는 세 가지 기본적인 접근법으로 사용할 수 있다.
- CUDA 가속 라이브러리 사용하기 → 다양한 domain에 대하여 높은 성능의 연산 라이브러리를 제공
- 컴파일러 지시문(compiler directives) 추가하기 → add a few lines of code
- C/C++의 확장인 CUDA 프로그래밍을 통해 코드 상에서 GPU 병렬처리 사용하기


** 참고로, CUDA 프로그래밍은 코드의 직렬 섹션이 CPU에서 실행되고, 병렬 섹션이 GPU에서 실행되는 하이브리드 모델이다.
2. What is cuDNN?
CUDA랑 cuDNN은 거의 짝꿍이다. 그럼 cuDNN은 무엇일까? cuDNN은 CUDA Deep Neural Network의 약자로, 심층 신경망(DNN)을 위한 GPU 가속 라이브러리이다.
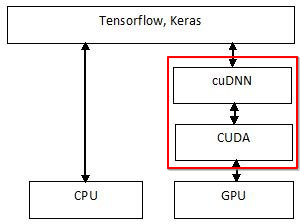
cuDNN은 computing tasks에 NVIDIA GPU를 사용하는 방법인 CUDA 프레임워크 위에 구축되어 있다. 한 마디로 CUDA를 통한 GPU 가속화 작업을 한층 더 최적화하는 라이브러리인 셈인데, 가령 pooling이나 convolution 연산 같은 딥러닝 기본 요소를 빠르게 이행할 수 있도록 하는 라이브러리이다.
우리에게 익숙한 Tensorflow나 Pytorch는 cuDNN 가속화 프레임워크에 포함되어 있다. CUDA가 GPU 컴퓨팅에 있어 일종의 컴파일러 역할을 수행하는 것처럼, cuDNN도 CUDA 프로그래밍 언어를 해석하고 딥러닝 프레임워크의 표준 함수 체계가 GPU acceleration을 사용할 수 있도록 해주는 것이다.

CUDA toolkit
여기서 문제!! 그럼 CUDA toolkit은 뭘까? 분명 Pytorch 같은 프레임워크를 설치하면서 같이 설치하는 명령어가 있었던거 같은데.. CUDA와 CUDA toolkit의 차이, 혹은 cuDNN과 CUDA toolkit의 차이는 아무도 궁금해하지 않아(...) 인터넷상에 정보가 없던 차에 NVIDIA 공식 docs 중 일부에서 찾을 수 있었다.

결론부터 말하자면 CUDA toolkit은 CUDA의 일부이다.
The CUDA software environment consists of three parts:
- CUDA Toolkit (libraries, CUDA runtime and developer tools) - SDK for developers to build CUDA applications.
- CUDA driver - User-mode driver component used to run CUDA applications (e.g. libcuda.so on Linux systems)
- NVIDIA GPU device driver - Kernel-mode driver component for NVIDIA GPUs.
- 출처 : https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/
위의 그림을 보면, linux에서 CUDA 드라이버와 GPU 커널모드 구성 요소들은 NVIDIA 디스플레이 드라이버 패키지에 함께 제공된다. 이 위에 빌드된 것이 CUDA toolkit인데, CUDA 라이브러리들 중 일부는 toolkit에 포함되어 있는 반면, 다른 일부는 cuDNN과 같은 형태로 독립적으로 출시될 수 있다고 한다.
출처 : https://kaen2891.tistory.com/20
https://gcapes.github.io/intro-cuda-python/01-introduction/
https://blog.roboflow.com/what-is-cudnn/