[DL] Topic modeling with BERTopic - 개요 및 알고리즘
LDA를 시작으로 문서에서 주제를 찾아내는 많은 technique들이 소개되어 왔다. 그중 State-of-art 토픽 모델링을 수행하는 BERTopic에 대해 소개해보려 한다.
논문은 없지만 개발자의 깃헙 페이지와 소스코드를 참고하면 이해에 도움이 된다. 본문은 깃헙 페이지에 소개되어있는 알고리즘 설명글을 토대로 작성되었다.
++ 수정: 2022.03.11 일자로 BERTopic 논문이 아카이브에 올라와있었다! https://arxiv.org/abs/2203.05794
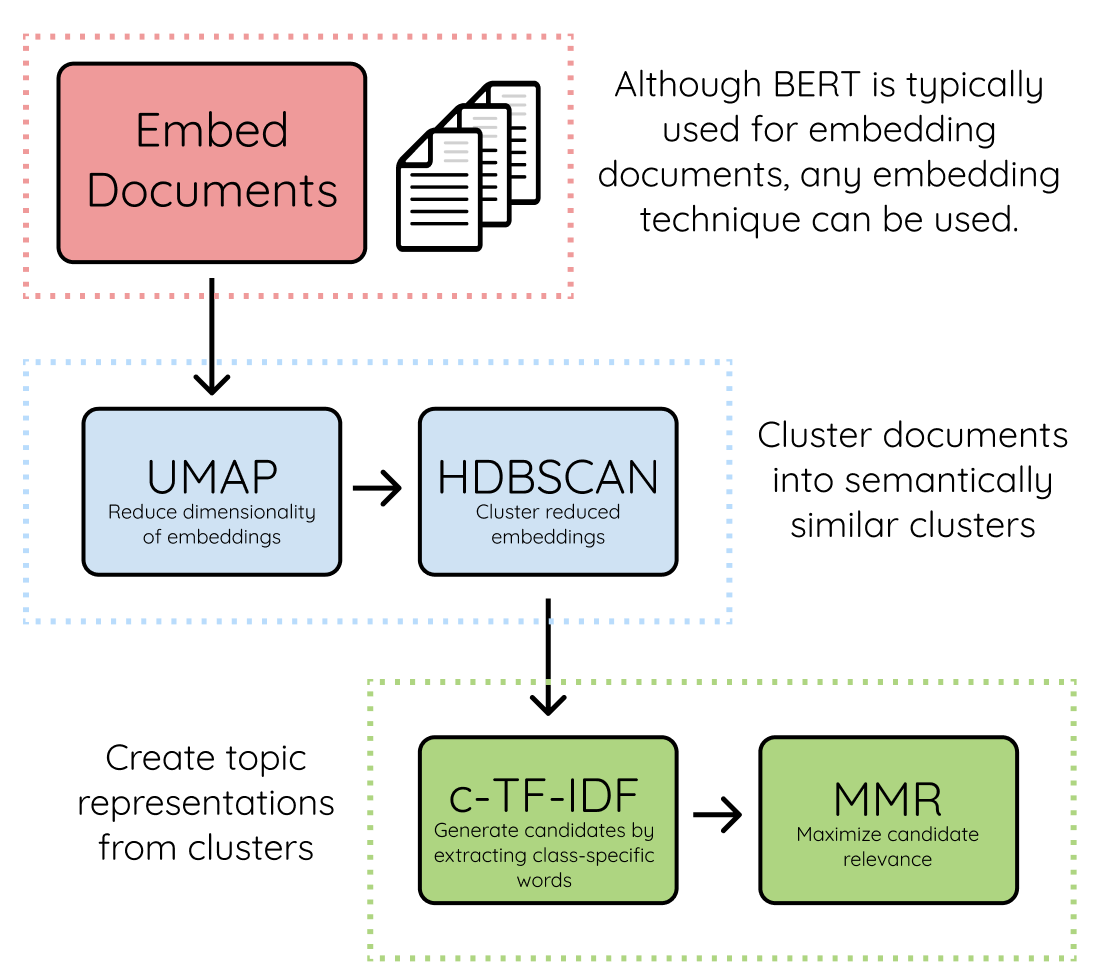
1. Embed documents
sentence-transformers를 이용해 문서 단위의 임베딩을 만든다. (궁금한점1: SBERT 논문을 보면 문장A와 B에 대해 평균 풀링 혹은 MAX 풀링으로 문장 단위의 임베딩을 만든다고 설명이 되어 있는데 문서 단위의 임베딩 how???) 사전학습된 모델인 BERT를 통해 임베딩 벡터를 얻기 때문에 다양한 언어들을 지원한다고 한다. default로 지정된 모델은
- "all-MinLM-L6-v2" (영어)
- "paraphrase-multilingual-MinLm-L12-v2" (50+ other languages)
지원가능한 다른 모델들은 이곳에서 볼 수 있다.
2. Cluster documents
2-1. UMAP (Uniform Manifold Approximation and Projection)
PCA나 t-SNE와 같은 차원 축소 알고리즘이다. 다만 PCA 같은 경우 matrix factorization이고, t-SNE와 UMAP은 neighbor graph를 기반으로 한다. 쉽게 말하면 데이터가 실제로 존재하는 n차원의 그래프를 더 낮은 차원의 비슷한 그래프로 축소시키는 것이다(construction of high dimensional graph and its mapping to a lower dimensional graph). 일반적으로 클러스터링 알고리즘은 고차원의 공간에서 클러스터링을 수행하는 데 어려움을 겪기 때문에, UMAP을 통해 임베딩의 local 및 global structure을 보존하면서 차원을 줄인다.
2-2. HDBSCAN (Hierarchical DBSCAN)
이렇게 축소된 임베딩을 HDBSCAN을 사용해 outlier를 식별하고 클러스터링한다. DBSCAN은 고차원의 nested clusters를 효과적으로 분류하기 위해 고안된 알고리즘으로, density 기반의 single-linkage 클러스터링을 이용해 클러스터 간 위계를 구성하고(hierarchical) 높은 유연성을 제공한다.
DBSCAN에서 클러스터는 density-connected point들을 최대로 포함하는 집합으로 정의된다. density-connected point는 다음과 같은 속성들로 구성되어 있다.
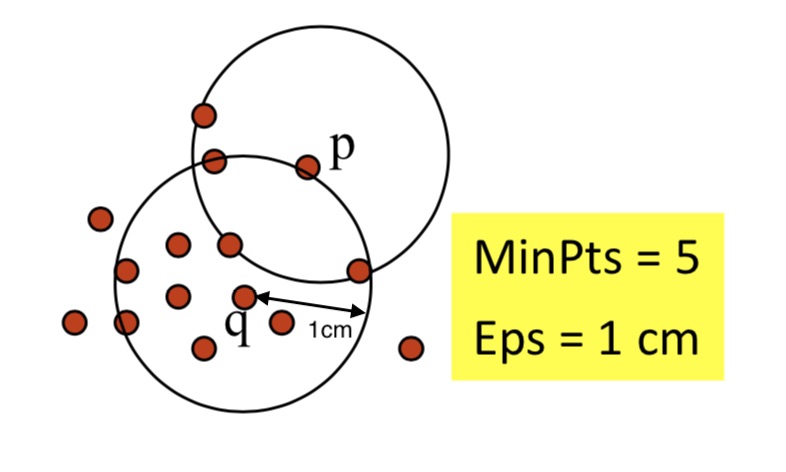
- \( Eps(\varepsilon) \): 클러스터에 이웃을 포함할 수 있는 최대 반지름 거리
- \( MinPts \): 클러스터를 형성하기 위해 필요한 최소 이웃 수
point q를 기준으로 클러스터 안에 포함된 number of points를 나타내는 함수는 다음과 같다.
$$ NEps(q) = \left\{p\: belongs\: to\: D|dist(p, q) \leq Eps\right\} $$
HDBSCAN의 경우 \( \varepsilon \) 파라미터는 더 이상 필요하지 않으며 MinPts만 존재한다. 하지만 DBSCAN 자체가 하이퍼파라미터를 휴리스틱하게 정하도록 만들어져 있기 때문에(\( \varepsilon \)와 \(MinPts\)에 따라 상당히 다른 결과를 보여줌) HDBSCAN 알고리즘을 최적화하는 과정에서도 인간의 직관이 필요하게 된다(...)
3. Create topic representation
구성된 클러스터들 안에서, 클러스터와 클러스터를 구분하기 위해 modify된 TF-IDF를 사용한다. TF-IDF는 문서 간 단어의 중요도를 비교하는 방법이다. c-TF-ICF는 단일 클러스터의 모든 문서를 단일 문서로 간주하고 TF-IDF를 적용한다. 필자가 이해하기로는, TF-IDF를 수행하기 위해 DTM matrix을 만들면서 구성되는 문서 인덱스를 클러스터 전체로 확장한다는 말인 것 같다. 이렇게 되면 산출된 matrix의 각 행은 해당 클러스터 내의 단어에 대한 중요도 점수가 될 것이고, 즉 클러스터 별로 가장 중요한 단어를 추출할 수 있게 된다. 이를 토픽에 대한 설명(각 토픽에 대한 word set)으로 볼 수 있다.

What we want to know from the clusters that we generated, is what makes one cluster, based on its content, different from another? To solve this, we can modify TF-IDF such that it allows for interesting words per cluster of documents instead of per individual document.
각 클러스터는 문서의 집합이 아닌 아니라 단일 문서로 변환된다. 그런 다음 클래스 \(c\)에서 단어 \(x\)의 빈도를 추출한다. 이것이 class-based tf가 된다. 뒤에 로그 변환된 식도 역문서 빈도를 계산하는 방법과 동일하다(클래스 A당 평균 단어 수를 모든 클래스에 걸친 단어 \(x\)의 빈도로 나눈 로그).
4. (Optional) Maximal Marginal Relevance Coherence
c-TF-IDF representation은 곧 클러스터(문서 set)를 설명하는 단어 집합을 뜻한다. MMR은 word set의 coherence를 개선하기 위해(단어들이 여러 집합에 걸쳐 겹치지 않게 하기 위해) 사용된다. 그 결과, 토픽에 관련되지 않은 단어들은 삭제된다. 그러니까 이 단계는 언어 모델의 coherence level을 향상시키기 위한 단계라고 이해하면 될 듯...
그리고 이 technique은 같은 단어의 수많은 변형을 줄이는데 도움을 주기도 한다고 한다(!) (궁금한점2: how??). 가령 game이라는 단어가 한 토픽에 등장했을 때 games나 gaming 등등 원형이 변형되었지만 사실상 같은 의미인 단어들이 함께 등장한다. MMR을 이용한 BERTopic은 최종 결과물에서 동의어의 수를 줄이고 단어 간 다양성을 높일 수 있다.
You can also use this technique to diversify the words generated in the topic representation. At times, many variations of the same word can end up in the topic representation. To reduce the number of synonyms, we can increase the diversity among words whilst still being similar to the topic representation.