[DL] 딥러닝 음성 이해 - Introduction to sound data analysis
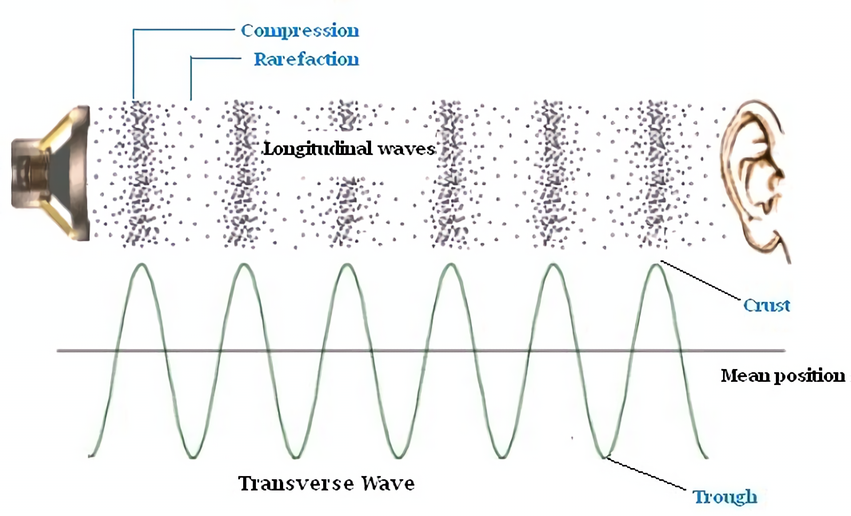
기본적으로, 소리란 진동에 의하여 만들어지는 파장(wave)이다. 물체가 진동하면 이웃한 공기의 분자들에 진동이 전파되고, 이 순환이 우리 귀에 들어오면 우리는 그것을 소리로 인식하게 된다. 즉, 소리는 파장으로 전파되는 기계적인 압력이라고 할 수 있다. 압력 변동의 강도를 시각화하기 위해 x축이 시간, y축이 진폭을 나타내는 그래프를 그려볼 수 있다.
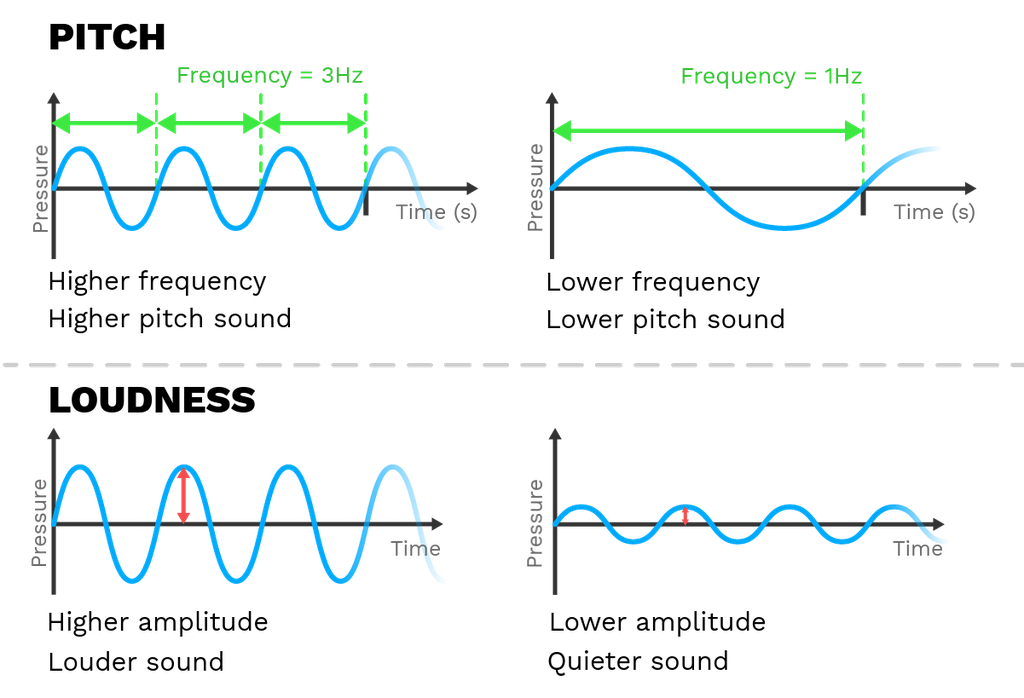
진폭(amplitude)는 파동의 진동 폭을 의미하며, 주파수(frequency)는 1초당 주기가 반복되는 횟수이다(참고로 주기란 sin파의 완전한 1회 cycle에 걸리는 시간을 의미한다). 위 그림에서 상단의 그래프는 주파수의 변화, 하단의 그래프는 진폭의 변화에 따른 소리의 표현을 그리고 있다.
- pitch - 음의 높낮이, 주파수가 클수록 빠르게 진동하고 있다는 뜻 → 높은 소리
- loudness - 음의 크기, 진폭이 클수록 크게 진동하고 있다는 뜻 → 센 소리
우리가 접하는 대부분의 소리들은 규칙적이고 주기적인 패턴을 따르지 않는다. 그리고 서로 다른 주파수 신호를 합쳐 더 복잡한 반복 패턴을 갖는 복합 신호가 생성되기도 한다.
1. Analog to Digital Conversion
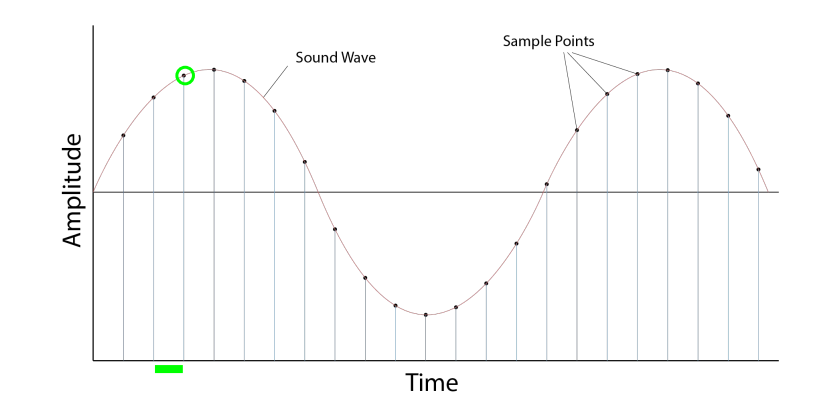
소리 에너지를 전류로 변환하는 것은 가능하지만, 전류 자체를 정보로 저장할 수는 없다. 딥러닝과 같이 컴퓨터 연산을 수행하기 위해서는 음파를 디지털화, 정확히는 일련의 숫자로 변환하는 과정을 거쳐야 한다. 이를 ADC(Analog to Digital Conversion; 정확히는 Converter을 지칭)라고 부르며, 일정한 시간 간격으로 소리의 진폭을 측정함으로써 이루어진다.
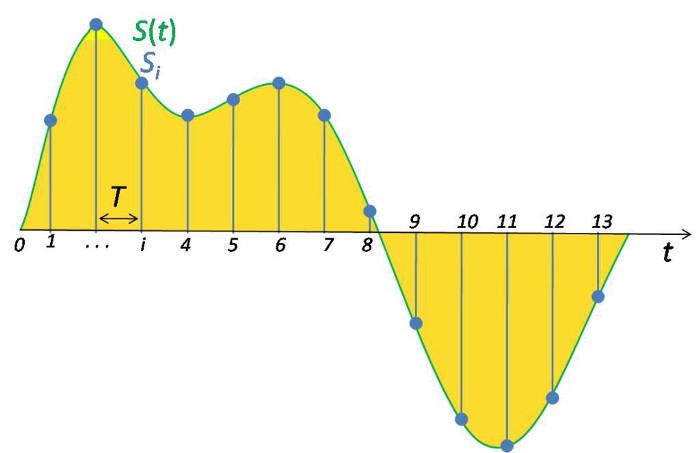
시간 \( t \)마다 측정된 진폭을 샘플(sample)이라고 한다. 샘플레이트(sample rate)는 초당 sample의 수인데, 가령 오디오 표준 sample rate인 44.1khz는 1초당 44100번의 sample들을 기록했다고 볼 수 있다. 이렇게 표본화된 데이터에 상응하는 숫자를 나열하게 되면 디지털 데이터가 완성된다.
푸리에 변환 (Fourier Transform)
말했듯이 우리가 일상에서 접하는 소리들은 대부분 복합신호이다. 푸리에 변환은 이러한 복합신호를 다양한 주파수를 갖는 주기함수들(sin 함수와 cos 함수)의 합으로 분해하여 표현하는 것이다.
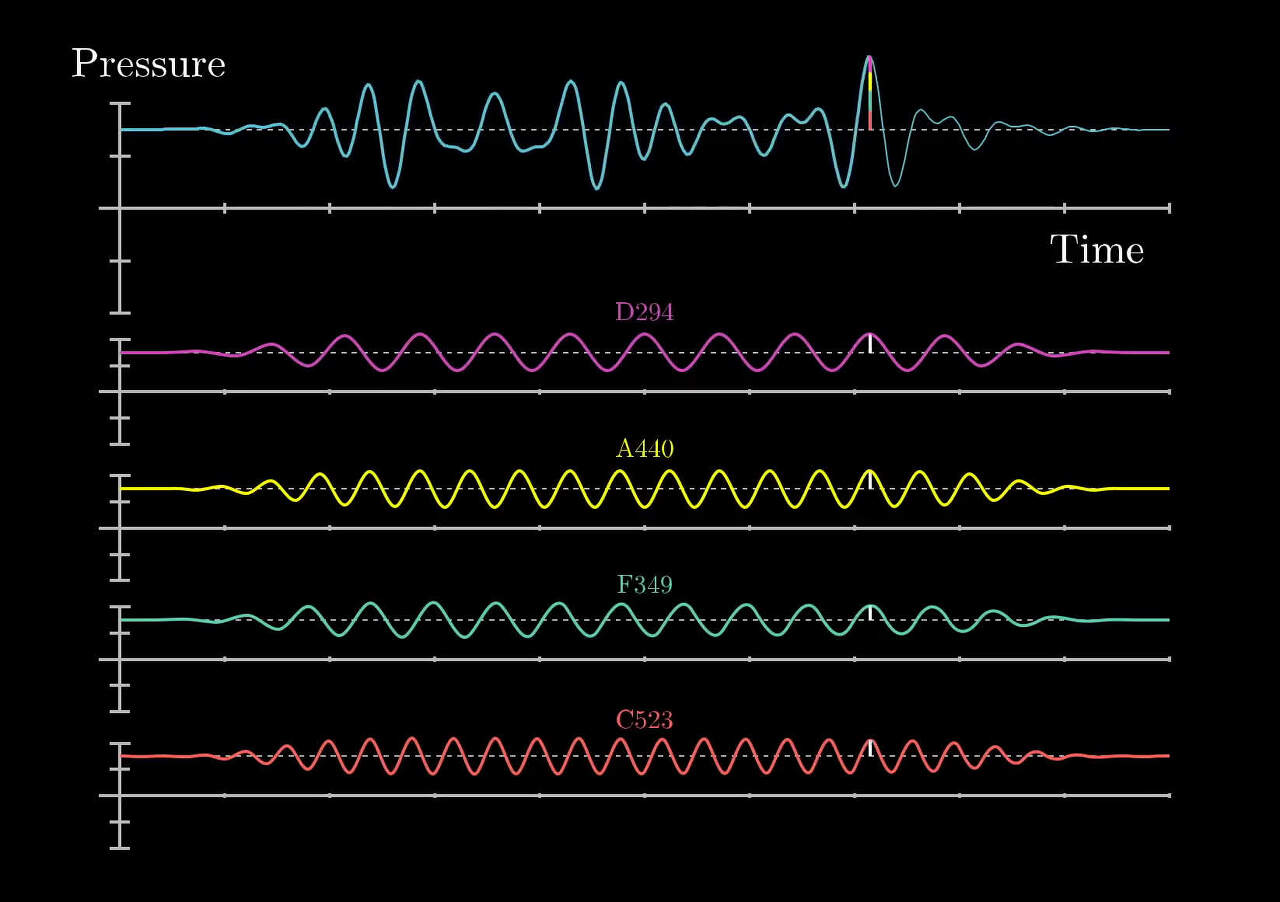
해당 그림에서 맨 위의 파란색 신호를 입력 신호라고 한다면, 아래 4개의 신호들은 푸리에 변환을 통해 얻어진 원본 신호를 구성하는 주기함수 성분들이 된다.
주기 \( T \)를 가지고, 반복적인(cyclic) 모든 함수 \( y(t) \)는 고유의 주파수와 진폭을 갖고 있는 복수의 지수함수의 합으로 나타낼 수 있다. (단, 주기 T는 무한히 커진다고 가정하기 때문에 비주기함수에도 푸리에 변환을 적용할 수 있다) 이 주기함수의 진폭을 구하는 과정을 푸리에 변환(Fourier Transform)이라고 한다.
$$ y(t) = \int_{-\infty}^{\infty} A_k \cdot e^{i 2\pi ft} $$
- \( f\) = 주파수(frequency) = \(\frac{1}{T} \)
\(k \)번째 주기함수의 진폭 \( A_n \)은 다음 식으로 계산한다.
$$ A_k = \int_{\infty}^{\infty} y(t) \cdot e^{-i 2\pi ft}dt $$
위의 푸리에 변환이 연속적이고 주기가 무한한 디지털 신호에 대해 계산된다면, 이산 푸리에 변환(Discrete Fourier Transform; DFT)은 주기가 \( T \)인 이산시간 시계열 데이터를 가정한다. 일반적으로 오디오나 EGG 등 신호 데이터는 연속적일 수 없는데, 기계를 통해 신호가 정보로 저장될 때 이미 이산적인 특징을 갖게 되기 때문이다(sampling). 따라서 이산적인 특징을 다룰 수 있는 DFT를 사용한다.
$$ y(t) \mapsto x(n) $$
$$ t = nT $$
여기서 \(N \)을 함수의 한 주기 \(T \)를 구성하는 총 sample 수이자 이 함수의 주파수 성분들의 총 갯수라고 하고, \( n\)을 함수의 sample의 순번이라고 했을 때(위 그림에서 초록색 동그라미로 표시된 것의 순번), DFT 공식은 다음과 같다.
$$ A_k = \sum_{n=0}^{N-1} x(n) \cdot e^{-i2 \pi fn \frac{k}{N}} $$
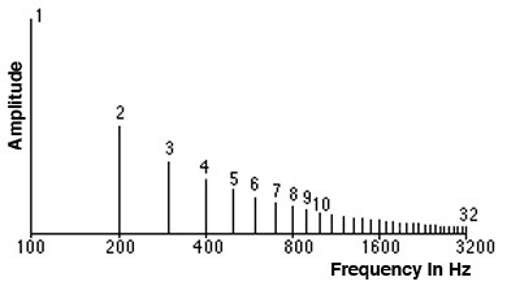
푸리에 변환을 이산화하여 계산을 수행하는 DFT 계산에 있어 삼각함수의 주기성을 이용해 계산속도의 효율을 높인 알고리즘이 고속 푸리에 변환(Fast Fourier Transform; FFT)이다. FFT는 무한 계산을 모두 수행하지 않고 동일한 값을 생략하는 기법으로 계산량을 줄였다. 보통은 로그 스케일로 표현된다.
그리고 이 FFT를 사용해 입력 신호를 [주파수-분포]의 frequency domain 그래프로 만든 것이 스펙트럼(spectrum)이다. (정확한 명칭은 x축이 주파수이고 y축이 power(amplitude)라서 Power spectrum이다. 여기서 로그를 취해주면 y축 단위가 데시벨(dB)로 바뀐다)
푸리에 변환은 결정론적인 시계열 데이터를 주파수 영역으로 변환하는 것을 말하지만 스펙트럼(spectrum)은 확률론적인 확률과정(random process) 모형을 주파수 영역으로 변환하는 것을 말한다. 따라서 푸리에 변환과 달리 시계열의 위상(phase) 정보는 스펙트럼에 나타나지 않는다.
스펙트럼을 추정할 때 사용하는 방법 중의 하나전체 시계열을 짧은 구간으로 나눈 뒤 깁스 현상을 줄위기 위해 각 구간에 윈도우를 씌우고 FFT 계산으로 나온 값을 평균하는 방법이다. 보통은 로그 스케일로 표현한다.
2. Audio Transformation
STFT (Short Time Fourier Transform)
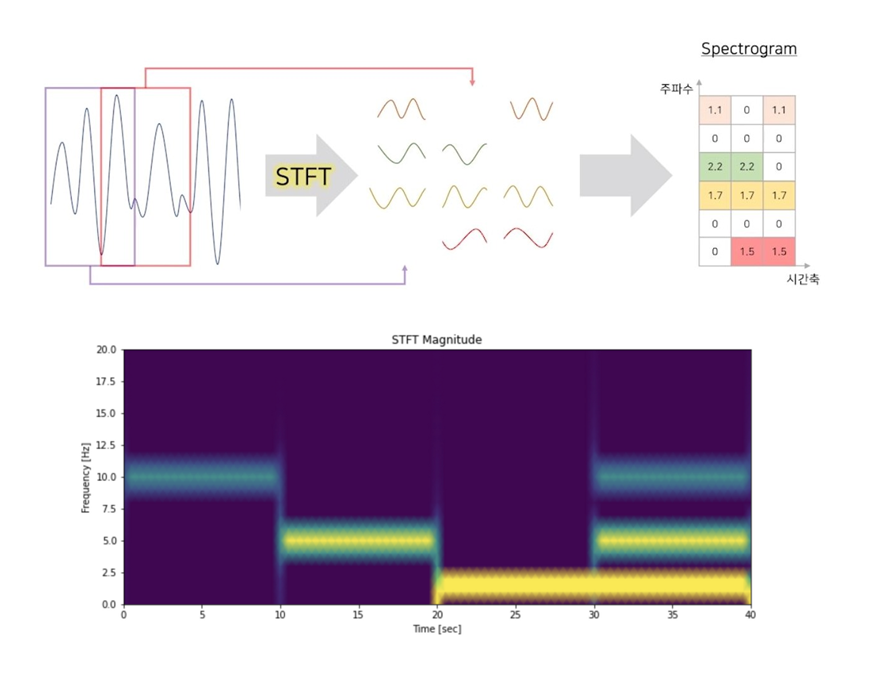
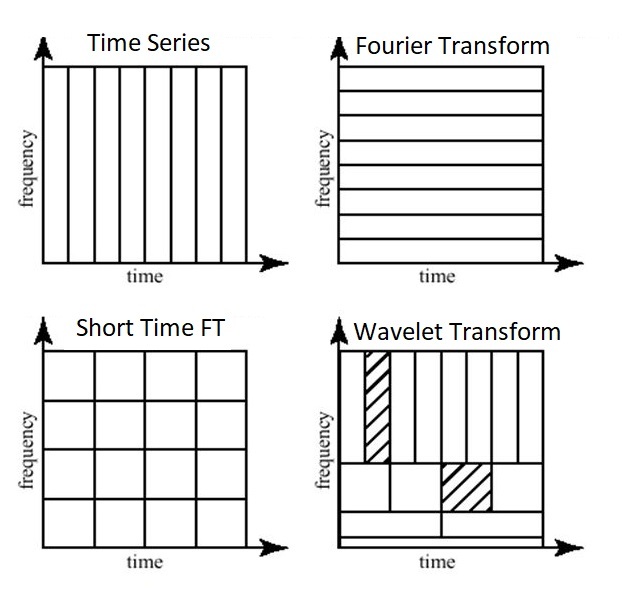
푸리에 변환만을 이용해 디지털 신호를 산출하는 것은 좋지 않은 방법인데, 시간 변화에 따른 주파수 변화를 반영하지 못하기 때문이다 (가령 위의 스펙트럼 그림을 보았을 때 32개의 주파수 성분이 한 신호를 형성하고 있다는 것만 알 수 있다. 각각의 주파수가 어느 시점에 존재하는지 여부는 알 수 없음). 스펙트럼은 [시간-진폭]의 그래프에서 주파수 단위로 파형들을 뽑아내기는 했으나 원래 x축에 해당하던 시간 특성을 잃어버렸다. 이때 STFT(Short Time Fourier Transform)는 원본 신호를 sliding window를 통해 짧게 잘라 푸리에 변환(정확히는 DFT)을 적용하는 방식으로 이를 해결하였다. 이렇게 x축이 시간, y축이 주파수가 되도록 STFT 데이터를 그래프로 나타낸 것을 스펙트로그램(spectrogram)이라고 한다. Spectrogram의 색은 시간축과 주파수 축의 변화에 따른 진폭의 차이(intensity of amplitude)가 되며, 3차원 데이터를 2차원으로 축약해 표현한 것이라고 할 수 있다.
$$ S(m, k) = \sum_{n=0}^{N-1} x(n+mH) \cdot w(n) \cdot e^{-i2\pi n\frac{k}{N}} $$
- \( H \) = hop size (window가 움직이는 너비)
- \( m\) = frame number (시간 프레임 인덱스)
CQT (Constant-Q Transform)
뒤에서 설명할 mel-spectrogram을 만드는 데 있어 전형적인 방법은 spectrogram에 STFT를 수행하는 것이다. 이것 말고도 다른 time-to-frequency analysis 방식이 있는데, CQT는 서로 다른 주파수 대역들 사이의 기하학적 분해를 고려한다.
표준 STFT에서 window function \(w(n)\)의 해상도는 주파수 대역의 모든 값에 대해 동일하다. 가령 베이스 드럼이든 심벌즈든 모든 \( x(n+mH) \)에 대해 동일한 frequency resolution을 적용하게 되는데, CQT는 인간 귀의 특성을 반영한다. CQT 기반의 스펙트럼 분석은 낮은 주파수 영역에서는 좁은 대역폭을 가지고, 높은 주파수 영역에서는 넓은 대역폭을 가진다 (이건 밑에서도 설명하는데, 인간은 낮은 주파수 영역의 소리에 더 민감하다, 따라서 낮은 주파수 대역폭을 고해상도로 분석하는 것이 인간의 귀 관점에서 현실적).
STFT 기반의 방식과 같이 낮은 주파수 영역의 해상도를 높은 주파수 영역에 적용하는 것은 시스템적인 낭비이다. 그래서 CQT에서는 주파수 마다 해상도를 달리하여 낮은 주파수대역에서는 STFT에 비해 좁은 영역을 분석함으로써 주파수특성에 대한 이점을 살려 더 많은 피크를 보존할 수 있고, 높은 주파수 영역에서는 STFT에 비해 넓은 영역을 한번에 분석함으로써 더 효과적으로 주파수 피크를 식별 할 수 있다.
- 출처 : 한국음향학회지 저널아티클 부분 발췌 (https://www.koreascience.or.kr/article/JAKO201417048538874.pdf)
식은 STFT와 크게 다르지 않다. 마찬가지로 \(m\)을 시간 프레임 인덱스, \(k\)를 주파수 bin 인덱스라고 했을 때
$$ S_{CQT}(m, k) = \sum_{n=0}^{N_k-1}w(n)x(n+mH)\cdot e^{-i2 \pi n\frac{Q}{N_k}} $$
- \( Q \) = 중심 주파수와 주파수 대역의 비율로 계산되는 상수 (constant-Q) - 보통 \( 45 < Q < 55 \)라고 함
wave를 단순히 정해진 window size로 자르지 말고 이 size를 변화시켜가면서 잘라야 한다는 개념은 wavelet transform과 일맥상통해, CQT도 wavelet transform의 일종이라고 여겨지는 듯 하다. 자세한건 나중에 공부하면서...
2-1. Mel-spectogram
소리의 주파수는 음의 높낮이로 구분된다. 고음은 저음보다 높은 주파수를 가지고 있는데, 인간은 소리를 인식할 때 고음보다 저음의 차이에 더 민감하다. 예를 들어 다음과 같이 서로 다른 소리의 쌍을 듣는 경우:
- 100Hz와 200Hz
- 1000Hz와 1100Hz
- 10000Hz와 10100Hz
세 가지 경우 모두 동일한 100Hz 차이가 나지만 100Hz와 200Hz 간 차이는 1000Hz와 1100Hz의 차이보다 더 극명하게 들릴 것이다 (10000Hz와 10100Hz의 차이는 아예 인식하지 못할듯;;). 그러나 200Hz 주파수가 100Hz의 두 배인 반면, 10100Hz 주파수가 10000Hz보다 1%밖에 높지 않다는 것을 생각하면 그리 이상한 일도 아니다. 즉, 인간은 주파수를 선형 척도가 아닌 로그 척도(log scale)로 인식한다는 것이다.
Mel-scale은 이를 감안해 다수의 사람들을 대상으로한 심리학적 실험을 진행해 개발되었다. 다음의 표는 실제 주파수(frequency)와 mel 단위 간 상관관계를 보여준다.
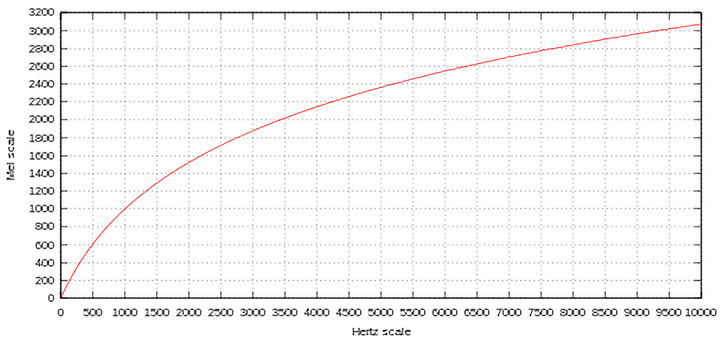
$$ m = 2595\cdot log(1+\frac{f}{500}) $$
$$ f = 700(10^{\frac{m}{2595}} -1) $$
소리의 또 다른 요소로는 세기가 있다. 소리의 세기는 진폭으로 나타내어지며, 마찬가지로 선형이 아닌 logarithmically 인식된다. 여기서는 데시벨(Decibel)이 소리의 세기를 측정하는 척도로 사용된다 (0dB는 완전 무음. 거기서부터 인식되는 단위가 기하급수적으로 증가하는데, 10dB는 0dB보다 10배, 20dB는 100배, 30dB는 1000배 더 크다).
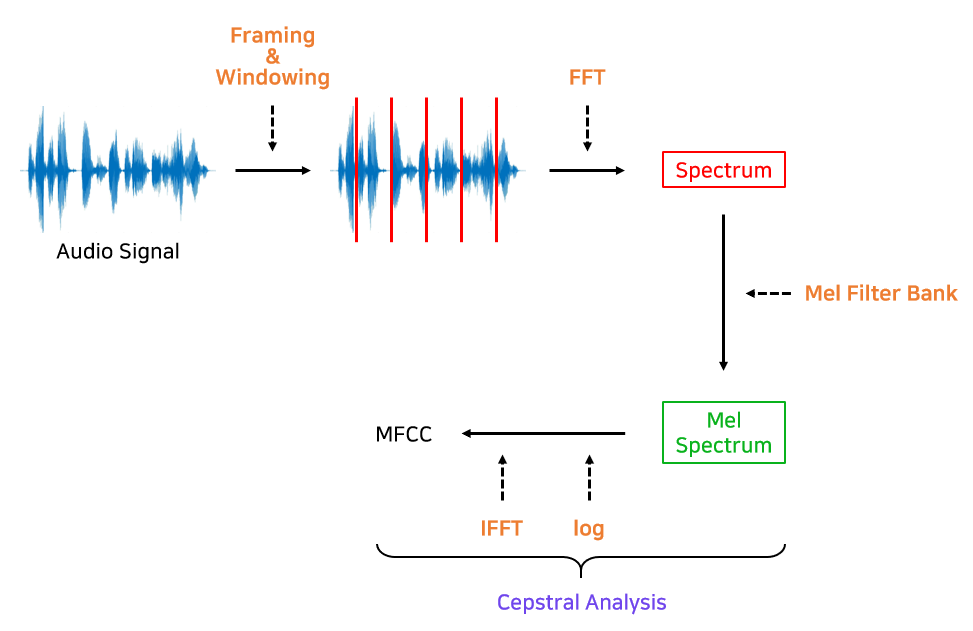
Mel-spectrogram이 하려는 것은 이 두 가지 요소인 mel-scale과 decibel-scale을 사용해 일반 spectrogram을 변형시켜 신호를 더 잘 표현하는 그림을 그려내는 것이다. 순서대로 나열해보면
- 일반 spectrogram에서 STFT 수행
- 주파수(Y축)를 mel-scale로 변환
- 색상을 decibel-scale로 변환
파이썬에서는 librosa라는 라이브러리가 다 해주지만 모든 걸 해주는 것은 아니다ㅎㅎ. Mel band 개수와 filter size 등 직접 지정해줘야되는 파라미터들이 있지만 자세한 건 다음 포스트에서 실습을 진행하며 설명하고자 한다^^
이렇게 생성된 mel-spectrogram은 사람의 perceptual distance를 잘 반영한다는 점에서 음성 인식부터 분류, 생성까지 다양한 sound processing 분야에 쓰이고 있다.
2-2. MFCC (Mel-Frequency Cepstral Coefficient)
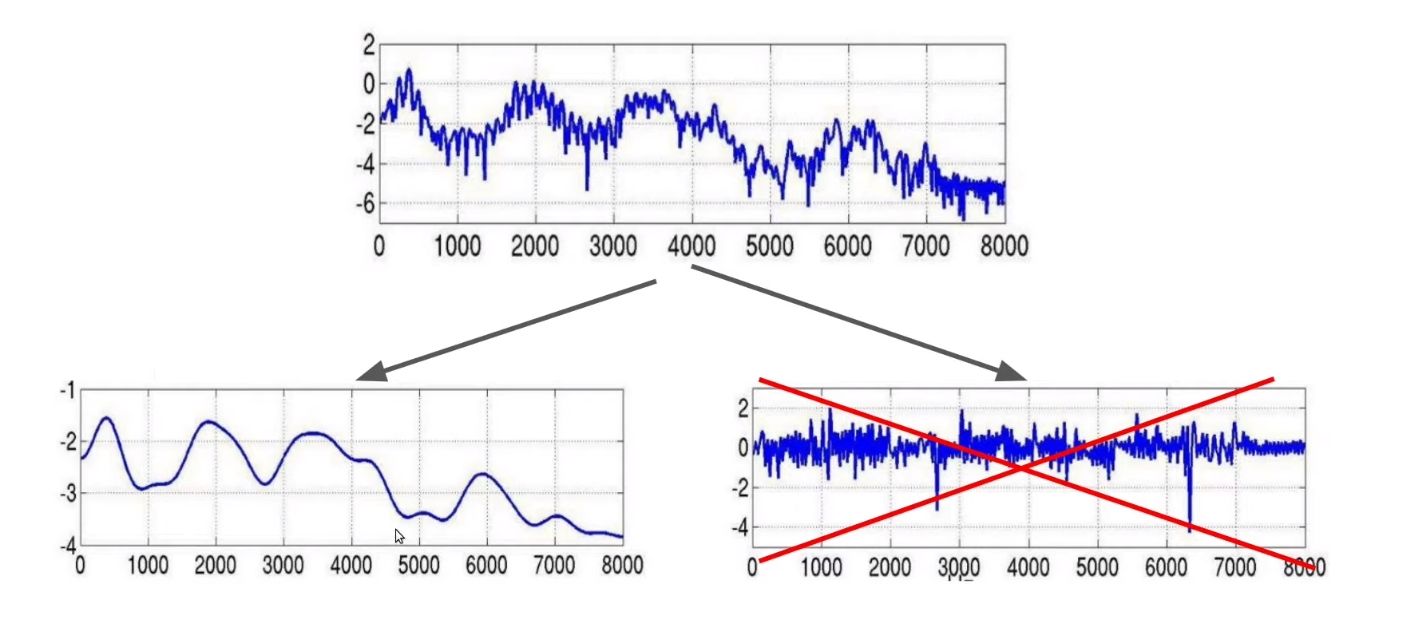
음성학에는 formants(형성음)라는 대역이 있는데, 요컨대 악기나 목소리에 특유의 음색을 주는 특정의 주파수대이다 (identity of sound). Formants는 음성 스펙트럼의 포락선(spectral envelople)을 살펴볼 때 쉽게 찾을 수 있으며, 포락선의 극점이 formants에 해당한다. 한편 log-spectrum에서 스펙트럼 포락선을 감하고 남은 주파수를 산출해보면 glottal pulse(성문파)가 나온다.
$$ X(t) = E(t) \cdot H(t) $$
$$ log(X(t) = log(E(t) \cdot H(t)) $$
Formants는 음성 인식이나 분류에 있어 중요한 특징이 되기 때문에 이를 관찰할 수 있는 spectral envelop을 추출해야한다. 위의 식에서 \( E(t)\)와 \(H(t) \)를 분리하는 과정에서 도출되는 것이 MFCC이다.
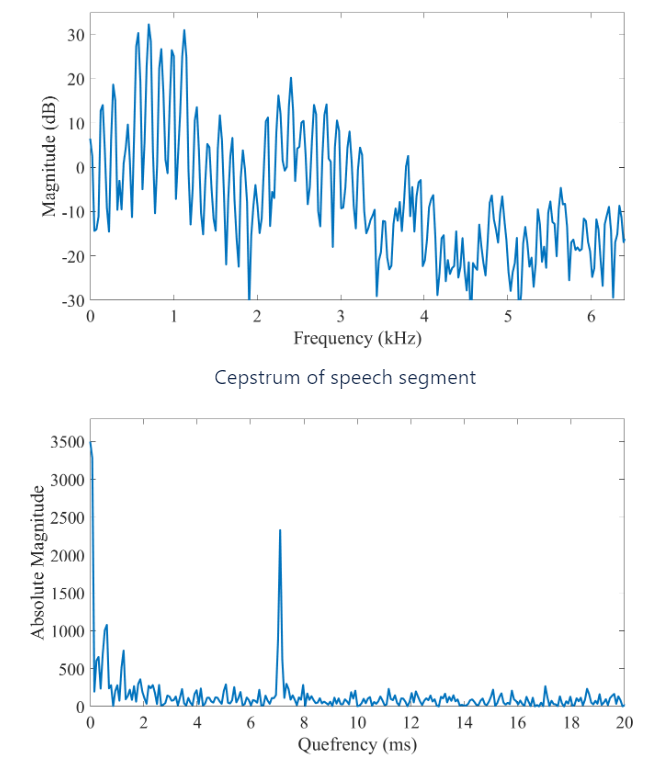
Log mel-spectrum에 역푸리에 변환(Inverse Fast Fourier Transform; IFFT)를 수행한 후 얻어지는 새로운 특성 그래프를 cepstrum이라고 한다. IFFT를 실시하면 상관관계가 높았던 주파수 도메인 정보가 새로운 도메인으로 바뀌어 이전 대비 상대적으로 변수 간 상관관계가 해소되게 된다. 다만 푸리에 변환과 역 변환간에는 상수배/켤레복소수 차이를 제외하면 차이가 없어 두 변환을 구분하는 것이 큰 의미가 없다는 점에서 IFFT 대신 DCT를 통상적으로 사용하게 된다.
DCT(Discrete Cosine Transform)는 DFT와 유사하지만 기저함수로 지수함수가 아닌 코사인 함수를 사용한다. DFT 대비 복소수 없이 실수로만 이루어져 있어 계산 속도가 빨라 신호처리 분야에서 자주 사용된다 (simplified version of FT).
DCT에 대해 찾아보면서 디지털 이미지 정보 압축 분야에서 많이 사용된다는 걸 알았는데, 데이터의 크기를 줄이면서 군더더기 컬러정보를 제거하기 위해 사용된다고 한다. 이미지 데이터에서 인간의 시각으로 인지 시스템에서 구분이 어려운 고주파(AC 성분)을 필터링해 최소화하고, 구분이 가능한 컬러 정보, 즉 컬러 데이터의 패턴에 영향을 주는 주요 성분(DC 성분 및 저주파 성분)을 분리할 수 있다. 반대로 IDCT를 수행함으로써 원본과 비슷한 데이터로 복원시킬수도 있다고 하니, 노이즈 제거 및 압축에 특화된 방식이라고 이해하면 빠를듯... (필자의 의견임)
You can think of the DCT as a compression step. Typically with MFCCs, you will take the DCT and then keep only the first few coefficients. This is basically the same reason that the DCT is used in JPEG compression. DCTs are chosen because their boundary conditions work better on these types of signals.

자료 출처 : https://datascienceschool.net/03%20machine%20learning/03.03.02%20%ED%91%B8%EB%A6%AC%EC%97%90%20%EB%B3%80%ED%99%98%EA%B3%BC%20%EC%8A%A4%ED%8E%99%ED%8A%B8%EB%9F%BC.html
https://newsight.tistory.com/199
https://www.edn.com/audio-pitch-shifting-the-constant-q-transform/
https://hyongdoc.tistory.com/403?category=884319