[DL] Attention 파헤치기 - Seq2Seq부터 Transformer까지 (2)
저번 포스트에서 Seq2Seq이란 무엇인지, 그리고 어텐션의 개념이 왜 등장하게 되었는지를 소개하고 어텐션 값을 계산하는 방법을 간단히 살펴보았다. 결국 어텐션이란 Query와 Key 간의 유사도를 측정하는 메커니즘라고 말할 수 있는데(필자는 이렇게 이해했다... 아닐수도ㅠ), 자연어처리 분야에서 어텐션을 활용한 대표적인 모델로 트랜스포머(Transformer)를 꼽을 수 있다.
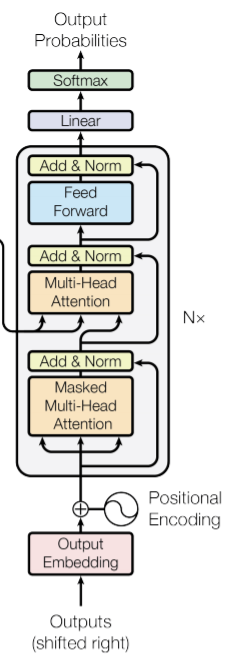
트랜스포머는 Seq2Seq의 인코더-디코더 구조를 가지고 있으며, 어텐션을 메인 아이디어로 고안된 모델이다. 2017년 구글이 발표한 "Attention Is All You Need" 논문으로 처음 소개되었다.
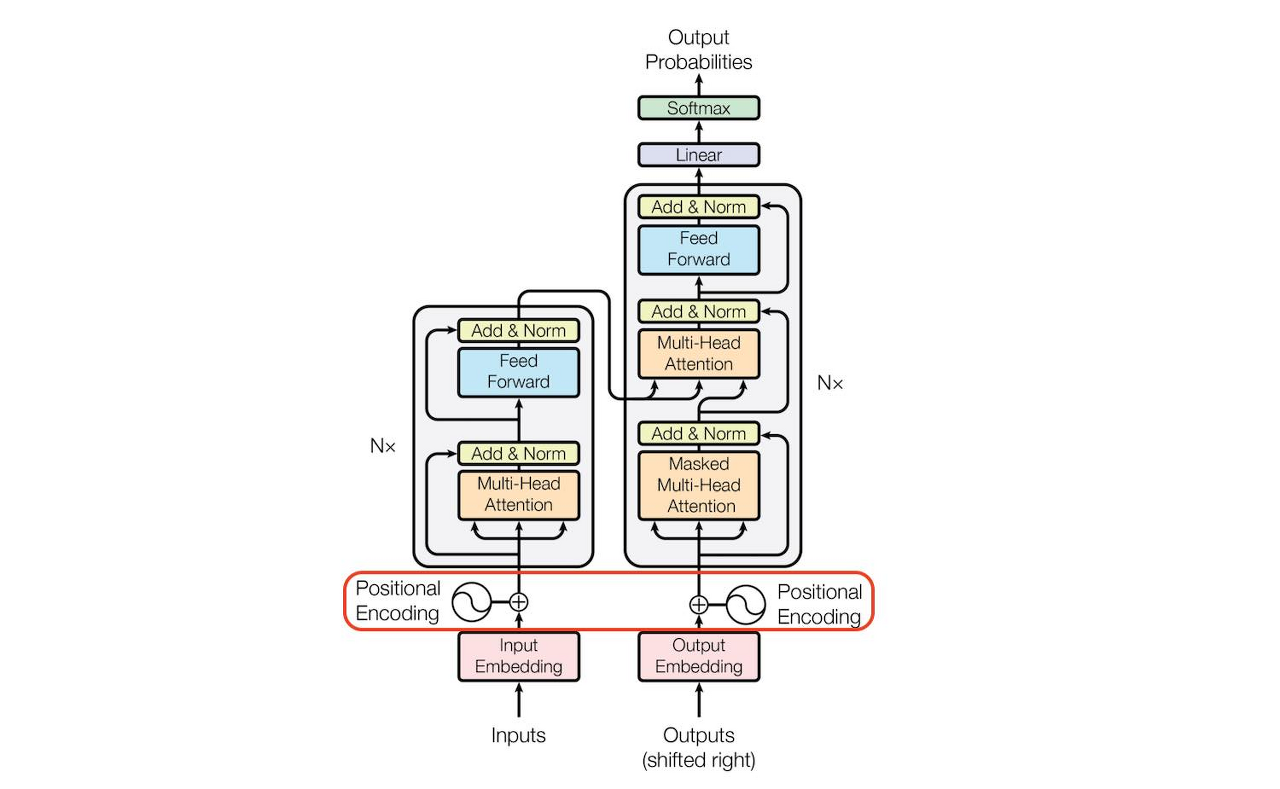
전체적인 구조

저번 포스트에서도 언급했지만,
- 인코더 - Multi-head Self-Attention (셀프 어텐션:계산된 값 디코더로 전송)
- 디코더 - Masked Multi-head Self-Attention / Multi-head Attention (셀프 어텐션과 인코더-디코더 어텐션 순차적으로 존재:인코더의 출력값은 인코더-디코더 어텐션의 입력값으로 사용됨)
어텐션 메커니즘이 어디서 어떻게 적용되는지 기억하자!
** 인코더와 디코더에 모두 들어가는 단계 **
Positional Encoding
인코더와 디코더에서 Attention layer에 들어가기 전, 입력값으로 주어질 단어 벡터 안에 단어의 위치 정보를 포함시키는 방법이다. 각 단어의 임베딩 벡터에 위치 정보들을 더하여 인코더/디코더의 입력으로 사용하게 된다.
어떻게? sin, cos값의 조합으로 순서값을 표현한다.

- 인덱스가 짝수인 경우: 사인 함수값 할당 => \( PE_{(pos, 2i)}=sin(\frac{pos}{10000^{2i/dmodel}}) \)
- 인덱스가 홀수인 경우: 코사인 함수값 할당 => \( PE_{(pos, 2i+1)}=cos(\frac{pos}{10000^{2i/dmodel}}) \)
Add & Norm
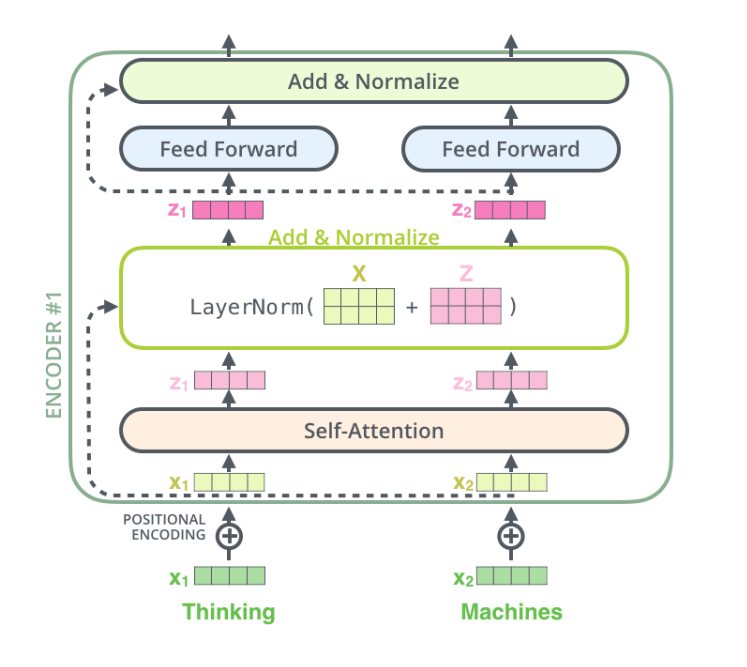
인코더와 디코더 각 서브층의 연결점에 있다. 말 그대로 Add와 Norm이 순차적으로 진행된다.
- 잔차 연결(Residual Connection) - 서브층의 입력과 출력을 \( f(x) + x \)의 구조처럼 더해주는 부분
- 층 정규화(Layer Normalization) - 텐서의 마지막 차원에 대해서 평균과 분산을 구하고, 이를 가지고 수식을 통해 값을 정규화하는 방식 \( LN = LayerNorm(x+sublayer(x)) \)
참고로 잔차 연결은 모델의 학습을 돕는 대표적인 기법으로, 뒤쪽까지 학습이 잘 전달되지 않는 것을 방지하기 위해 사용한다(이미지넷의 ResNet에서처럼).
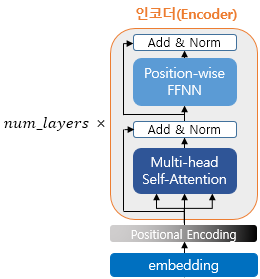
1. Encoder
2개의 서브층으로 구성 (1개의 어텐션 + 1개의 FFNN)
Multi-head Self-Attention
dot-product Self-Attention(내적 셀프 어텐션) 구조가 중첩된 형태이다. 입력받는 Q, K, V를 어텐션 헤드 수(하이퍼파라미터이다)만큼 나누어 병렬적으로 계산하는 것이 핵심이다.
1. Q, K, V를 헤드 수만큼 나누어
2. Linear layer를 통과시키고
3. 내적 어텐션(오른쪽 그림의 Scaled Dot-product Attention)을 구해 합친다.
이렇게 되면 어텐션을 여러 개 만들어 다양한 특징에 대한 어텐션을 볼 수 있다고 한다.
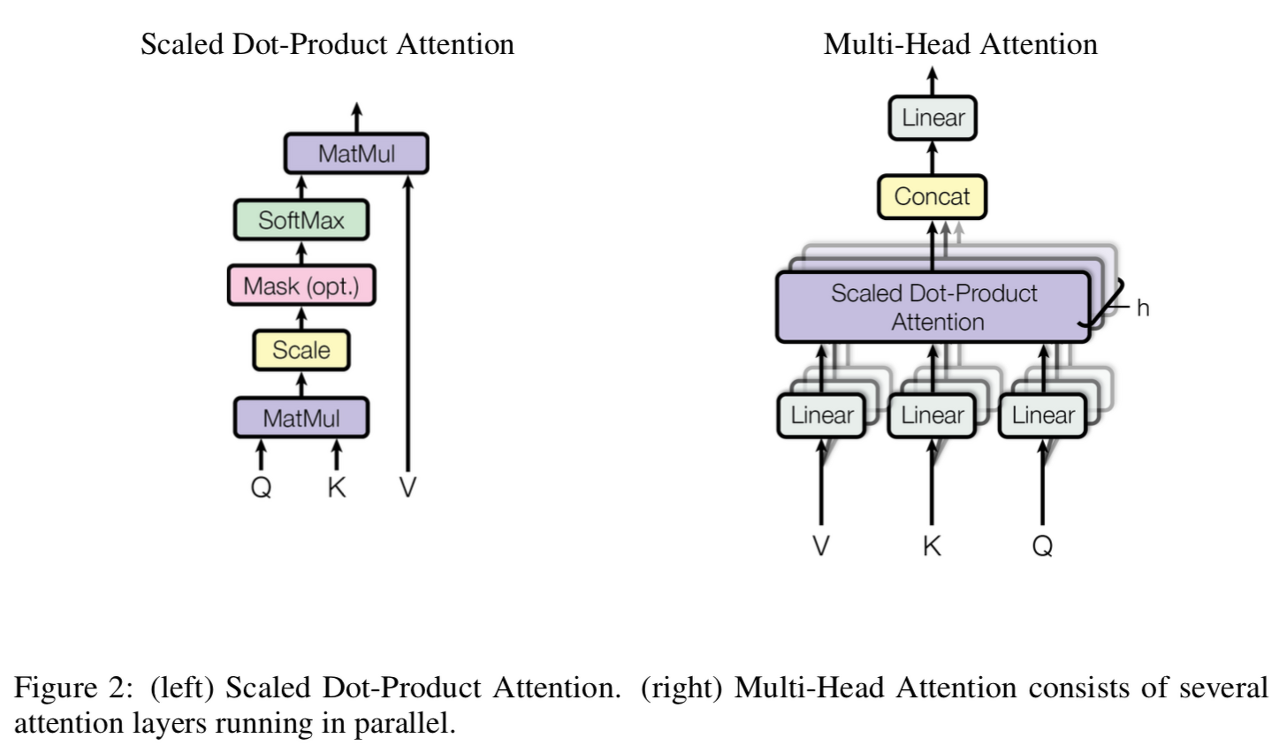
- Scaled dot-product Attention: 다른 것은 다 dot-product Attention과 같으나 Q와 K를 내적한 값에 K 벡터의 차원 수를 제곱근한 값으로 나눈 후 softmax 함수 적용
$$ Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V $$
Q와 V를 내적한 값이 벡터의 차원이 커지면서 학습이 잘 안될 수 있기 때문에 벡터 크기에 반비례하도록 크기를 조정하는 과정이다.
Position-wise FFNN
multi-head attention으로 나온 다양한 정보들을 합쳐주는 역할을 한다. 한 문장에 있는 단어 토큰 벡터 각각에 대해 연산해주기 때문에 position-wise라고 한다. 두 개의 Linear layer와 활성화 함수 ReLU를 활용한다.

2. Decoder
3개의 서브층으로 구성 (2개의 어텐션 + 1개의 FFNN)
- 첫 번째 Masked Self-Attention: 디코더의 입력 사이의 관계를 계산하는 셀프 어텐션
- 두 번째 Multi-head Attention: 인코더와 디코더의 관계를 확인하는 어텐션
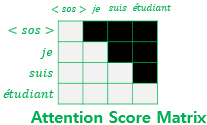
Subsequent Masked Attention (순방향 마스크 어텐션)
순환신경망 기반 Seq2Seq 구조는 자동으로 자신보다 앞에 있는 단어만 참고해서 단어를 예측하지만, 트랜스포머의 경우 전체 문장이 한번에 들어간다(순차적으로 들어갔다면 positional encoding 단계는 필요가 없었을지도).
seq2seq는 크게 인코더와 디코더라는 두 개의 모듈로 구성됩니다. 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터로 만드는데, 이를 컨텍스트 벡터(context vector)라고 합니다. 입력 문장의 정보가 하나의 컨텍스트 벡터로 모두 압축되면 인코더는 컨텍스트 벡터를 디코더로 전송합니다. 디코더는 컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력합니다.
...
RNN이 자연어 처리에서 유용했던 이유는 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 RNN의 특성으로 인해 각 단어의 위치 정보(position information)를 가질 수 있다는 점에 있었습니다.
하지만 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있습니다.
- 출처 : https://wikidocs.net/24996
따라서 트랜스포머에서의 경우, 자기보다 뒤에 있는 단어를 참고하지 않도록 뒤에 있는 단어에 대한 관계 정보를 보이지 않게 만들 필요가 있다. 이것을 마스킹 기법이라 부르고, 마스킹 기법이 적용된 어텐션이 디코더 첫번째 서브층인 Masked Multi-head Self-Attention이다.
Encoder-Decoder Attention
앞선 포스트에서도 강조했지만 셀프 어텐션과 인코더-디코더 어텐션을 헷갈리지 말자(...) 디코더의 두번째 서브층은 인코더-디코더 어텐션이다. K, V를 인코더의 마지막 층에서, Q를 디코더의 첫번째 서브층에서 가져온다.

최종적으로는 이런 식의 내적 연산을 거칠 것이다.

자료 출처: https://wikidocs.net/31379
https://velog.io/@jekim5418/NLP-Transformer#add--norm--feed-forward