[통계] 단순선형회귀(Simple Linear Regression)
단순선형회귀
하나의 변수와 다른 또 하나의 변수간의 관계를 분석하는 방법 - 종속변수 Y와 하나의 독립변수 X 사이의 관계를 연구
1. 공분산과 상관계수
종속변수 Y와 독립변수 X로 구성된 n개의 관측개체를 가지고 있다고 할때, Y와 X 간 연간관계의 방향과 강도를 측정해보자. 이때 등장하는 것이 공분산(covariance)와 상관계수(correlation coefficient)이다.

공분산
두 변수간의 관계에 대한 방향을 나타냄
$$ Cov(Y,X) = \frac{\sum_{i=1}^{n} (x_i-\overline{x})(y_i-\overline{y})} {n-1} $$
- \( Cov(Y,X) > 0 \)이면, Y와 X 사이에 양의 관계(우상향)
- \( Cov(Y,X) < 0 \)이면, Y와 X 사이에 음의 관계(우하향)
- \( -1 < Cov(Y,X) < 1 \)을 만족
상관계수
두 변수간의 관계가 얼마나 강한지 측정 (절댓값이 높을수록 산포도의 점들이 밀집되어 있다고 보면 될듯..)
표본평균을 \( \overline{x} \)와 \( \overline{y} \)로, 표본표준편차는 \( SD_{x} \)와 \( SD_{y} \)로 나타낼 때, 두 변수간의 상관계수 \( \gamma \)는 다음과 같다.
$$ \gamma = \frac{\sum_{i=1}^{n} (x_i-\overline{x})(y_i-\overline{y})}{\sqrt{\sum_{i=1}^{n} (x_i-\overline{x})^{2}}\cdot \sqrt{\sum_{i=1}^{n} (y_i-\overline{y})^{2}}} $$
해당 식의 분모와 분자를 각각 자유도 \( n-1 \)로 나누면
$$ \gamma = \frac{\sum_{i=1}^{n} (x_i-\overline{x})(y_i-\overline{y}) / (n-1)}{{SD_x}\cdot {SD_y}} $$
즉,
$$ \gamma = \frac{Cov(Y,X)}{{SD_x}\cdot {SD_y}} $$
2. 단순선형회귀모형
종속변수 Y와 독립변수 X의 관계는 다음과 같은 선형모형으로 가정될 수 있다.
$$ Y = \beta_0 + \beta_1{X} + \varepsilon $$
또, 각 관측개체는 다음과 같이 표현될 수 있다.
$$ y_i = \beta_0 + \beta_1x_i + \varepsilon_i, i = 1, 2, ..., n $$
- \( \beta_0 \)와 \( \beta_1 \)은 모수(parameter) - 상수
- \( \varepsilon \)은 확률변동(random disturbance) 혹은 오차(error) - 실제 자료와 참회귀선 \( y = \beta_0 + \beta_1x \)의 차이
모수에 대한 추정
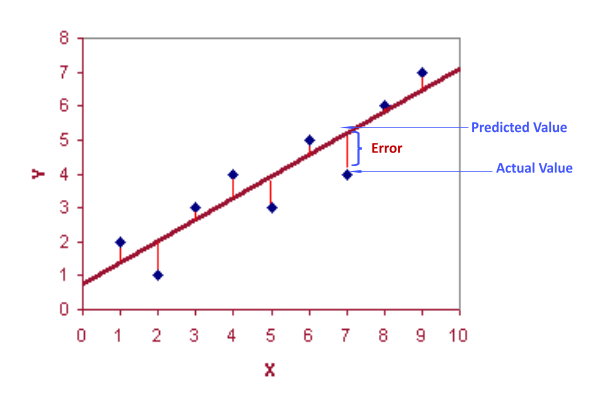
우리는 관측된 연구의 범위 내에서 선형방정식이 Y와 X 사이의 참 관계에 대하여 만족스러운 근사를 제공한다고 가정한다. 또, 오차항은 평균이 0, 표준편차는 \( \sigma \)인 정규분포를 따른다고 가정한다. 오차항은 종속변수 Y와 독립변수 X에 독립(independent variable)이기 때문이다. 주어진 자료를 잘 표현하는 회귀계수, 즉 모수들을 찾으려면 종속변수 대 독립변수의 산점도에 있는 점들을 가장 잘 표현하는 직선을 찾는 것이 중요한데, 통상적으로는 최소제곱법(least squares method)를 이용한다. 최소제곱법? 최소자승 추정량? 이름 헷갈림... 같은건 맞겠지..?
이 방법은 각 점으로부터 구하고자 하는 최적의 직선까지의 수직거리(vertical distance)의 제곱합을 최소로 하는 직선의 방정식을 제공한다. 다시 말하면 RMSE(root-mean-square error)를 최소화 하는 것!
- RMSE : 실제값과 예측치의 차이가 어느 정도 될지 알려주는 수치 - 회귀의 표준오차(standard error of regression)$$ RMSE = \sqrt{ \frac{\sum_{i=1}^{n} (y_i - \hat{y_i})^{2}}{n-2}} $$
\( S(\beta_0, \beta_1) \)을 최소로 하는 값 \( \hat{\beta_0} \), \( \hat{\beta_1} \)은 다음과 같이 구할 수 있다.
$$ \hat{\beta_1} = \frac{\sum (y_i - \overline{y})(x_i - \overline{x})}{\sum (x_i - \overline{x})^{2}} $$
$$ \hat{\beta_0} = \overline{y} - \hat{\beta_1}\overline{x} $$
잔차, MSE, RMSE, 그리고 오차
- 잔차(residual) : 실제 관측값 \( y_i \)와 그 추정치 \( \hat{y_i} = a+bx_i \)간의 차이.
- 평균-제곱 오차(MSE) : 잔차를 제곱하여 더한 잔차제곱합(SSE)를 자유도로 나눈 것. $$ \hat{\sigma^{2}} = MSE = \frac{SSE}{n-2} = \frac{1}{n-2}\sum_{i=1}^{n} (y_i - \hat{y_i})^{2} $$
- 제곱근-평균-제곱 오차(RMSE) : MSE에 제곱근을 취한 것. $$ \hat{\sigma} = RMSE = \sqrt{MSE} = \sqrt{\frac{SSE}{n-2}} = \sqrt{\frac{1}{n-2}\sum_{i=1}^{n} (y_i - \hat{y_i})^{2}} $$
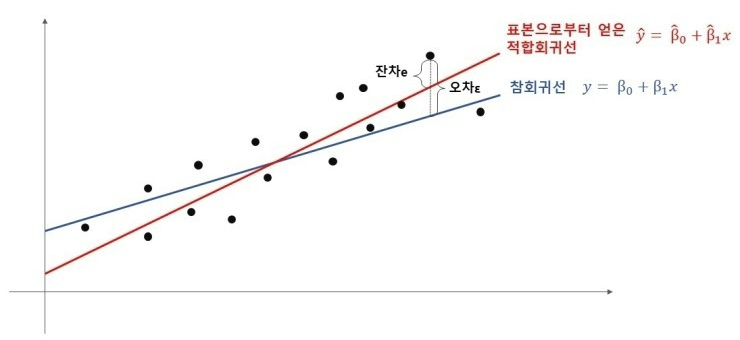
잔차 vs 오차?
오차(error)는 모집단(population)으로부터 추정한 회귀식으로부터 얻은 예측값과 실제 관측값의 차이를 이야기 합니다. 여기서 집중하셔야 할 점은 '모집단으로부터' 입니다. 즉 오차는, 추정한 회귀식과 모집단에서의 관측값의 차이를 말합니다.
잔차(residual)는 표본(sample)으로 추정한 회귀식과 실제 관측값의 차이를 말합니다. 사실상 현상을 분석할때, 모집단의 모든 데이터를 축적하기 보다, 일부의 데이터(표본집단)에서 회귀식을 얻기 때문에, 잔차를 기준으로 회귀식의 최적의 회귀계수를 추정합니다.
- 출처: https://jangpiano-science.tistory.com/116
위에서 모수를 추정하기 위해 사용한 최소제곱법은 '잔차'를 가지고 회귀식의 최적의 파라미터 값들을 추정하는 방법이다. 즉, 모집단으로부터 회귀식을 추정하는 것이 아니라 표본으로부터 회귀식을 얻을 때 사용하는 것이라고 할 수 있다! 사실상 실제 모집단의 모든 자료를 계산해 선형회귀식을 구하는 것은 불가능하다. 따라서 우리는 모집단에서 n개의 표본을 추출해 이 n개의 자료, 즉 표본자료에 대한 선형회귀식을 구해야 한다.
오차(\( \varepsilon \))란 실제 자료와 참회귀선의 차이를 말한다. 우리가 얻은 회귀선은 표본으로부터 얻은 적합값(fitted value)을 기반으로 한 회귀선이다. 잔차(e)란 실제 자료와 적합회귀선의 차이를 말한다.
3. 결정계수
결정계수(coefficient of determination) \( R^2 \)은 모형의 적합정도를 수치적으로 제안한다. Y와 독립변수들의 집한 \( X_1, X_2, ..., X_p \) 사이의 선형관계에 대한 강도는 Y와 \( \hat{Y} \)의 산점도를 탐색함으로써 평가될 수 있는데, Y와 \( \hat{Y} \)의 상관계수 \( \gamma \)는 다음과 같이 주어진다.
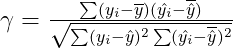
- \( \overline{y} \) - 종속변수 Y의 평균
- \( \overline{\hat{y}} \) - 적합값의 평균
결정계수 \( R^2 = \gamma^2 \)은 다음과 같다.
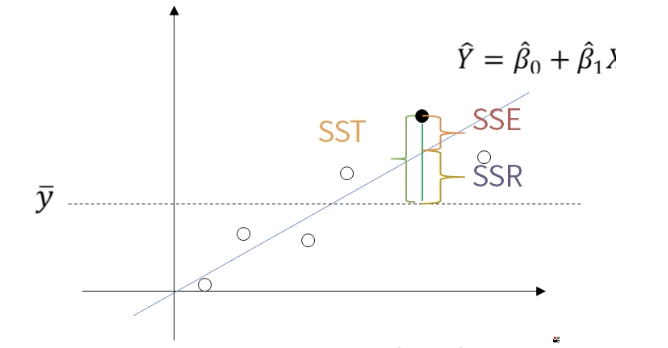
$$ R^2 = \frac{SSR}{SST} = 1 - \frac{SSE}{SST} = 1 - \frac{\sum (y_i - \hat{y_i})^2}{\sum (y_i - \overline{y})^2} $$
- 모형이 데이터에 잘 적합된다면 \( R^2 \)의 값은 1에 가까울 것이다.
- 참고로 SST는 SSE + SSR로, Y의 총 변동(SST)은 직선으로 설명 불가능한 변동 SSE와 직선으로 설명 가능한 변동 SSR로 되어있다.
- \( \hat{y} \)는 y의 평균을 의미
$$ SST = \sum (y_i - \overline{y})^2 $$
$$ SSR = \sum (\hat{y_i} - \overline{y})^2 $$
$$ SSE = \sum (y_i - \hat{y_i})^2 $$
4. 유의성 검정
개별 계수 추정치의 표준오차
단순회귀분석 모형에서 우리는 자료로부터 상수항과 기울기를 구한다. 다시 말하면, 입력시키는 자료가 바뀌면 출력되는 상수항과 기울기도 바뀐다. 여기서 규칙성을 찾을 수 있을까? 자료로부터 구한 상수항과 기울기의 추정치는 자료가 바뀜에 따라 얼마나 변하는가? 이를 표준오차(standard error; SE)로 구할 수 있다. 상수항 추정량의 표준오차는 자료에 걸쳐 상수항의 추정치가 얼마나 변할지 전형적인 크기를 알려주고, 마찬가지로 기울기 추정량의 표준오차는 자료에 걸쳐 기울기 추정치가 얼마나 변할지 전형적인 크기를 알려준다.
상수항과 기울기 추정량의 표준오차를 각각 SE(\( \beta_0 \)), SE(\( \beta_1 \))로 표시하면 다음과 같다.
$$ SE(\beta_0) = \sigma\sqrt{\frac{1}{n} + \frac{\overline{x}^{2}}{\sum_{i=1}^{n} (x_i - \overline{x})^{2}}} $$
$$ SE(\beta_1) = \frac{\sigma}{\sqrt{\sum_{i=1}^{n} (x_i - \overline{x})^{2}}} $$
표준오차 자체의 추정치를 각각 SE(\( \hat{\beta_0} \)), SE(\( \hat{\beta_1} \))으로 표시하면
$$ SE(\hat{\beta_0}) = \hat{\sigma} \sqrt{\frac{1}{n} + \frac{\overline{x}^{2}}{\sum_{i=1}^{n} (x_i - \overline{x})^{2}}} $$
$$ SE(\hat{\beta_1}) = \frac{\hat{\sigma}}{\sqrt{\sum_{i=1}^{n} (x_i - \overline{x})^{2}}} $$
여기서 \( \sigma \)는 회귀분석 오차의 표준편차이고 \( \hat{\sigma} \)는 RMSE이다.
개별 계수에 대한 추론
단순회귀분석 모형에서의 추정결과의 보고:
$$ \hat{y} = \beta_0 + \beta_1x $$
이때, \( \beta_0=SE(\beta_0) \)이고 \( \beta_1=SE(\beta_1) \)
관측지수=\( n \), 결정계수=\( R^{2} \), 추정의 표준오차=\( \hat{\sigma} \)
근데 저러면 \( \hat{y} = \beta_0 + \beta_1x \)이 되는게 아니라 \( \hat{y} = \hat{\beta_0} + \hat{\beta_1}x \)가 되는게 맞지 않나...? 밑에 SE도 그렇고...
이제 위 \( \beta_0 \)와 \( \beta_1 \)의 표본분포를 가지고 Y에 대해 X의 유용성을 평가하는 유의성 검정을 수행할 수 있다. 이는 정규성 가정 하에 성립한다.
- 귀무가설 - \( H_0 : \beta_1 = 0 \) (기울기가 0이라는 거니까, x가 y를 설명하는데 무용지물이라는 뜻이다)
- 대립가설 - \( H_1 : \beta_1 \neq 0 \)
논리전개상 일단 귀무가설이 맞다고 가정하자. 이제 귀류법으로 y에 대한 예측자로서 x의 유용성을 입증해야 한다. 귀무가설을 검정하기 위한 검정통계량(test statistics)은 다음의 t-검정 통계량이다. t-값은 자료에서 구한 추정치와 귀무가설 하에서 주어진 값의 차이를 그 추정치의 표준오차 단위로 나타내는 것을 잊지말자!
$$ t_1 = \frac{\hat{\beta_1}}{SE(\hat{\beta_1})} $$
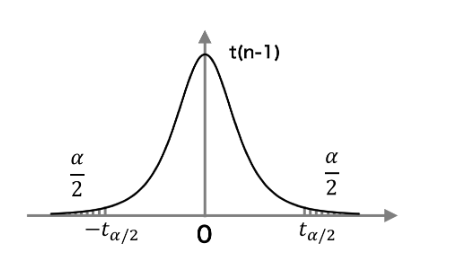
통계량 \( t_1 \)은 귀무가설이 사실이라는 가정 하에서 자유도가 \( n-1 \)인 t-분포를 따른다. 이를 t-분포표로부터 얻어진 적절한 임계값(critical value) \( t_{(n-2,\alpha/2)} \)을 비교함으로써 검정을 수행할 수 있다. 다음이 성립할 경우 유의수준 \( \alpha \)에서 \( H_0 \)가 기각된다.
$$ \left | t_1 \right | \geq t_{(n-2,\alpha/2)} $$
혹은 t-검정의 p값과 \( \alpha \)를 비교하여 \( H_0 \)를 기각시킬 수도 있다.
$$ \rho(\left | t_1 \right |) \leq \alpha $$