리눅스든 윈도우든 저장 장치 안의 데이터에 접근할 때 일반적으로 직접 저장 장치에 접근하지 않고 파일 시스템을 통해 접근한다. 이게 무슨 뜻일까? 파일 시스템이 없다고 가정하면, 메모리에 있는 데이터를 저장 장치에 저장할 때 데이터를 보관한 주소와 사이즈를 스스로 기억하지 않으면 안된다. 이렇게 되면 사용자에게 매우 성가신 일이 아닐 수 없다.
파일 시스템은 사용자에게 의미가 있는 하나의 데이터를 이름, 위치, 사이즈 등의 보조 정보를 추가하여 파일(file)이라는 단위로 관리한다. 그리고 어느 장소에 어떤 파일을 배치할지 등의 데이터 구조는 사양으로 미리 정해, 커널 안에서 이 파일 시스템을 다룬다. 이러한 프로세스 덕분에 사용자는 파일의 위치나 사이즈 등 복잡한 정보를 기억하지 않고 파일의 이름만으로도 저장 장치에 읽거나 쓸 수 있다.
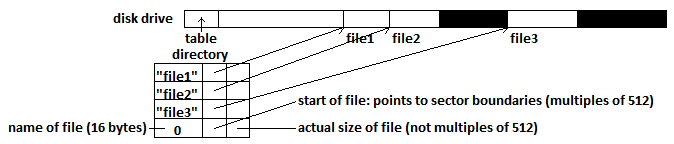
가령 사용자가 파일을 읽고 싶다면, 파일 읽기 시스템 콜을 날려 파일 이름과 파일 상의 오프셋 및 사이즈를 지정해 파일 시스템을 다루는 처리가 해당 데이터를 찾아 사용자에게 전달해줄 수 있다.
- 데이터(data) : 사용자가 작성한 문서나 사진, 프로그램 등의 내용
- 메타 데이터(meta data) : 파일의 이름이나 저장 장치 내의 위치, 사이즈 등의 보조 정보
1. Linux Directory Structure
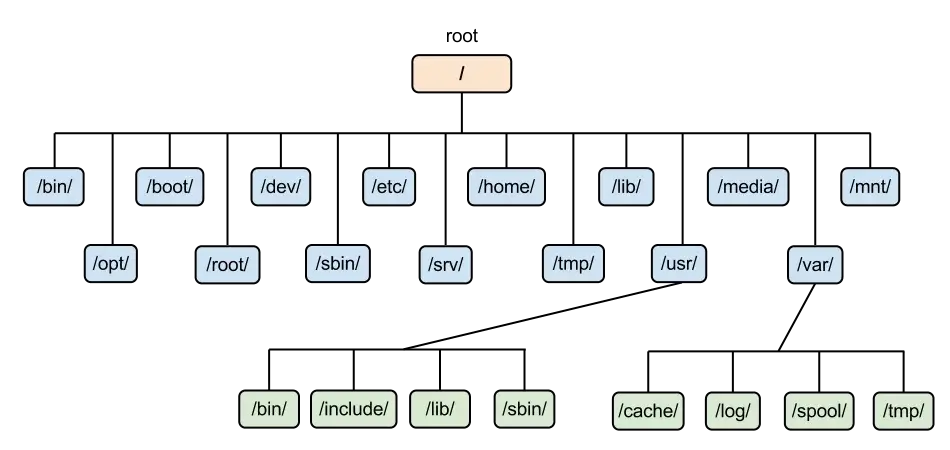
파일을 카테고리별로 정리할 수 있도록 리눅스의 파일 시스템(윈도우도 마찬가지)에는 파일을 보관하는 특수한 파일인 디렉터리(directory)가 존재한다. 디렉터리 트리(directory tree)란 루트 디렉터리 아래에 파일 및 하위 디렉터리가 존재하는 계층 구조를 이른다. 반면, 차이점으로는 물리 디스크가 몇 개든 리눅스에서는 언제나 시스템 전체에 단 하나의 트리만 가지게 된다는 점이다(윈도우에서는 디스크가 2개면 디렉터리 트리도 2개이다. 그래서 C:\, D:\ 처럼 저장 장치별로 별도의 트리 구조를 갖게 됨).
1-1. FHS (Filesystem Hierarchy Standard)
FHS는 리눅스의 파일 시스템 계층을 정의하는 표준 사양이다. /usr 및 /bin과 같은 최상위 하위 디렉터리에 대한 최소 요구 사항과, 해당 디렉터리에 위치해야 하는 파일과 symbolic link를 지정한다. FHS 호환 운영 체제에서 모든 파일과 디렉터리는 루트(단일 슬래시 '/')라는 최상위 디렉터리에 라우팅된다. 참고로 대부분의 리눅스 배포판은 FHS를 따르지만 현재 대부분의 배포판은 제안한 표준을 완전히 따르지는 않는다고 한다(가령 NixOS는 고유한 계층 구조를 사용해 Nix 패키지 관리자의 파일 시스템에 리눅스를 설치한다고 한다)
2015년에 업데이트된 가장 최신 버전인 FHS 3.0은 여기를 참고:
https://refspecs.linuxfoundation.org/FHS_3.0/fhs/index.html
1. 주요 디렉터리
| /bin | 일반 사용자 및 관리자가 사용하는 주 명령어의 실행 파일이 배치되어 있음 (e.g. cat, ls, cp) |
| /dev | 디바이스 파일이 배치되어 있음 (디바이스 파일 - 디스크나 키보드 등 하드웨어를 다루기 위한 특수 파일) |
| /etc | 리눅스와 애플리케이션 설정 파일이 배치되어 있음 |
| /home | 사용자별로 할당되는 홈 디렉터리 사용자의 이름이 hee라면 해당 사용자의 홈 디렉터리는 /home/hee가 된다. |
| /sbin | /bin과 비슷하게 실행 파일을 포함 + 관리자용 명령어 (e.g. init, shutdown) |
| /tmp | 임시 파일용 디렉터리. 참고로 이 디렉터리 안의 파일을 삭제하도록 설정된 배포판도 있으므로 중요한 파일을 /tmp에 보관하면 안된다. |
| /usr | 읽기 전용 사용자 데이터 및 설치한 애플리케이션의 실행 파일, 문서, 라이브러리 등이 위치. 루트와 비슷한 보조 계층 구조를 갖고 있다. - /usr/bin : 모든 사용자의 비 필수 명령어 실행 파일 - /usr/sbin : 비 필수 시스템 실행 파일 - /usr/etc : 비 필수 유틸리티와 파일 |
| /var | 변화하는 데이터를 저장하기 위한 디렉터리. 애플리케이션 실행 중에 만들어진 데이터나 로그 등이 이곳에 저장된다. |
2. 기타
| /boot | 부팅 과정에서 필요한 실행 파일들을 포함. |
| /lib | 부팅과 시스템 운영에 필요한 공유 라이브러리(shared library)와 커널 모듈(kernel module) 위치. |
| /media | 이동식 미디어의 마운트 지점. |
| /mnt | (루트 파일 시스템에 연결된) 임시 마운트 포인트 디렉터리. |
| /opt | Add-on(선택 가능한) 애플리케이션 소프트웨어 패키지가 설치됨. |
| /proc | 시스템에서 운영되고 있는 다양한 프로세서와 프로그램 정보를 포함. /proc은 커널이 메모리 상에 만들어 놓은 것으로, 디스크에는 존재하지 않는다. |
| /root | 루트 사용자 홈 디렉터리. |
| /srv | 시스템에서 제공하는 사이트별 데이터 위치. |
2. Linux File System
2-1. inode
리눅스의 디폴트 파일 시스템인 ext 계열 파일 시스템에 대해 알아보기 전에 inode 구조를 설명할 필요가 있다. inode는 Unix 스타일의 파일 시스템에서 파일이나 디렉터리와 같은 파일 시스템 개체를 표현하는 자료구조이다. disk block들에 대한 위치 정보들을 기록한 index block을 따로 사용하는 인덱스 블록 기법(indexed allocation)과 유사하다. inode 구조에서는 inode block이라는 것을 생성해 파일들에 대한 inode를 관리한다.
모든 파일이나 디렉터리는 반드시 inode를 하나씩 가지게 된다. inode에는 파일의 정보(접근 권한, 소유주, 크기, inode 번호 등)가 저장되는데, 간단히 말하면 해당 파일의 메타 데이터를 가지고 있다고 볼 수 있다. 사용자는 외부적으로 파일 이름만 아는 상태로 파일을 읽고 쓰지만, 내부적으로는 inode 정보를 참조해서 처리된다. 위의 ext2 inode 구조 그림을 바탕으로 포함되는 속성은 다음과 같다:
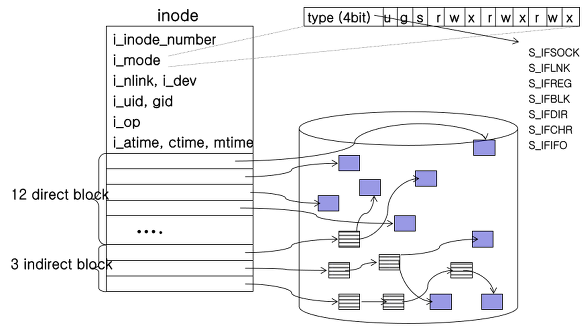
- i_inode_number : 파일이 생성되자마자 부여되는 inode 번호
- i_mode : 해당 inode가 관리하는 파일의 속성 및 접근 제어 정보
- i_nlink : 해당 inode를 가리키고 있는 파일 수(혹은 링크 수)
- i_uid : 파일을 생성한 소유자의 user ID
- i_gid : 파일을 생성한 소유자의 group ID
- i_op: 해당 inode의 함수 오퍼레이션 주소
- i_atime, i_ctime, i_mtime : 파일의 접근시간, 생성시간, 수정시간
i_mode - File mode
16bit로 구성된 i_mode 변수는 리눅스의 file permission management와도 연관이 깊다.
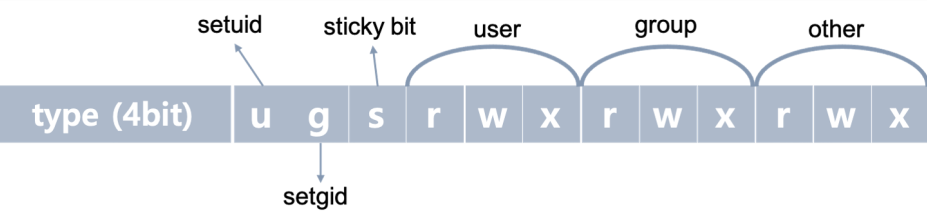
- 상위 4bit : 파일의 유형 (S_IFREG(-)-정규파일, S_IFDIR(d)-디렉터리, S_IFLNK(l)-링크파일 등)
- u : setuid(set user id) bit; 파일이 수행될 때 (일시적으로) 파일을 생성한 사용자의 권한으로 동작할 수 있게 함
- g : setgid(set group id) bit; 파일이 수행될 때 (일시적으로) 파일 소유 그룹의 멤버로의 권한으로 동작할 수 있게 함
- s : sticky bit; 해당 bit가 설정된 디렉터리에는 누구든 파일을 저장할 수 있으나, 파일 삭제는 해당 파일 소유자만 가능하도록 함
- 하위 9bit : 파일의 접근 제어에 사용(순서대로 읽기(r)-쓰기(w)-실행(x))
i_block[15] field
inode 하단부에는 i_block[15] 필드가 존재하는데, 이것은 파일에 속한 disk block들의 위치를 관리하기 위해 사용된다. i_block[15]은 총 15개의 엔트리가 존재하며, 12개는 직접 블록(direct block)이고 3개는 간접 블록(indirect block)이다.
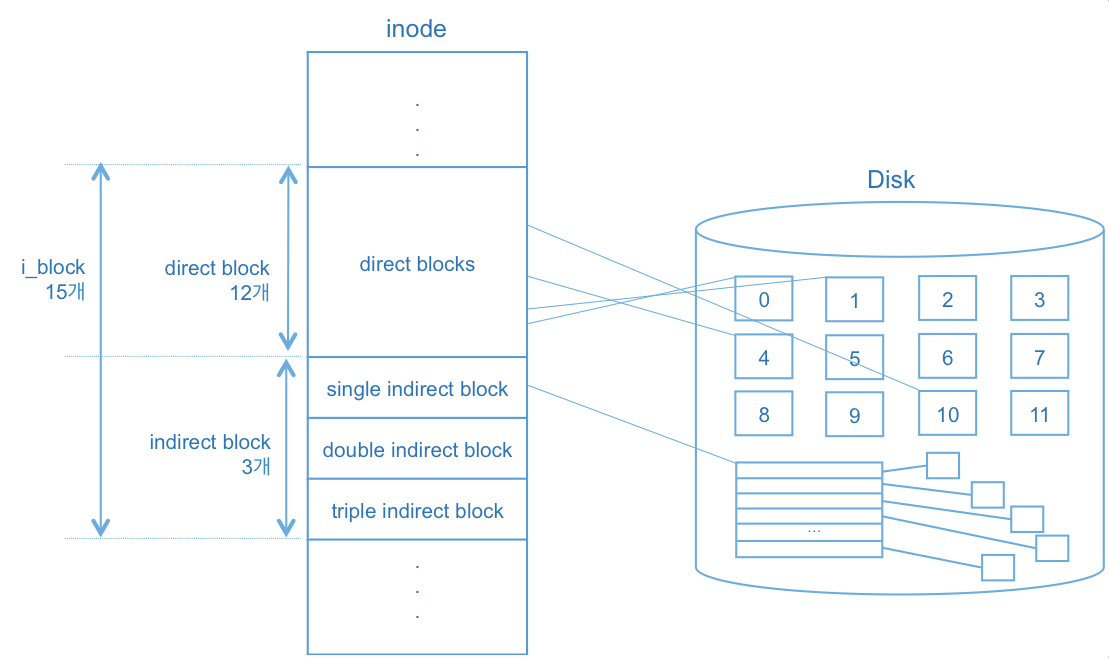
- 직접 블록(direct block): 실제 파일의 내용을 담고 있는 디스크의 data block을 가리키는 포인터 변수
- 간접 블록(indirect block): disk block을 가리키는 포인터들을 갖는 블록인 index block을 가리키는 포인터 변수
- single indirect block - 하나의 index block을 가짐
- double indirect block은 2중의, triple indirect block은 삼중의 index block을 가짐
위의 그림에서 각 data block의 크기가 4KB라고 가정하면, direct block으로 지원할 수 있는 파일의 크기는 \( 4KB \times 12 = 48KB \)이다. 반면 single indirect block의 경우 하나의 index block을 갖는데, 이 index block도 결국 disk block에 존재하므로 4KB의 크기를 가진다. 그리고 각각의 포인터를 위해 4byte를 할당하게 되면 \( 4KB \div 4byte = 1024 \)개의 포인터가 존재하게 된다. 즉, single indirect block으로 지원할 수 있는 파일의 크기는 \( 4KB \times 1024 = 4MB \)가 된다. 같은 방식으로 계산하면 triple indirect block은 4TB만큼을 지원할 수 있다.
이와 같이 계산하면 이론상 리눅스의 inode 구조가 지원할 수 있는 파일의 최대 크기는 \(48KB + 4MB + 4GB + 4TB \)가 된다. 반대로 파일의 크기가 48KB 미만인 경우 별도의 index block을 디스크에서 읽어올 필요가 없기도 하다. inode가 매우 깔끔하고 효율적으로 설계되어 있는 자료구조임을 알 수 있다.
※ 참고
당연하지만 실제 리눅스가 저 정도의 파일 사이즈를 지원해주지는 않는다(...) 리눅스 커널 내부의 파일 관련 함수들이 사용하는 변수나 인자들이 32bit로 구현되어 있기 때문에 4GB의 제한을 갖는다고 한다.
2-2. ext 계열 파일 시스템 (extended file system)
ext2
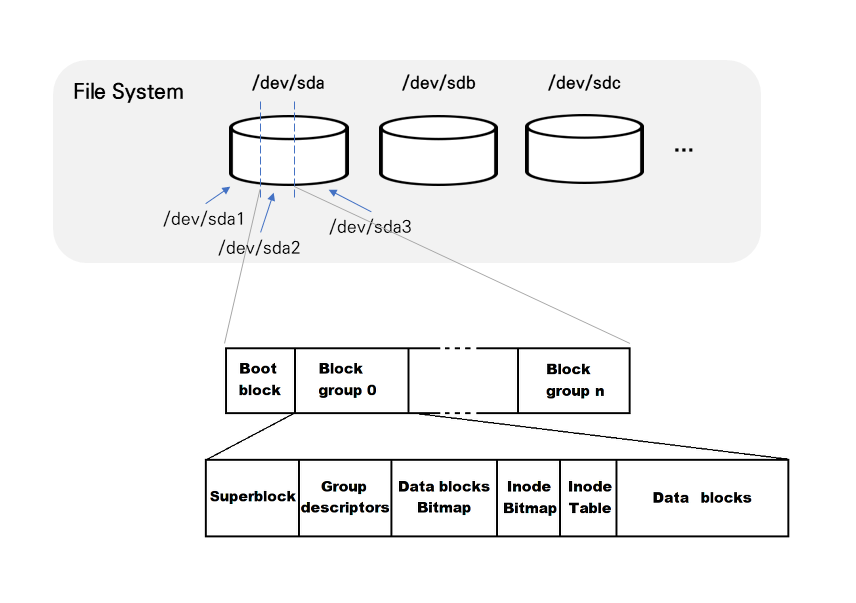
ext2 파일 시스템을 기반으로 향상된 버전이 ext3, ext4이기 때문에 ext2의 세부 구조에 대해 알아두면 나머지도 이해하기 쉽다(여기에 덧붙여서 저널링만 이해하면 됨). 위 그림은 SCSI방식의 디스크가 장착된 시스템 구조를 나타낸 것이다. 이는 /dev 디렉터리에 들어가보면 확인할 수 있다.

SCSI방식의 디스크는 "sd"라는 이름으로 접근이 되고, 첫번째 디스크부터 순서대로 sda, sdb, sdc, ... 식으로 이름이 붙는다.
디스크가 시스템에 장착되면, 하나의 물리 저장장치인 디스크를 여러 디스크 공간인 파티션(partition)으로 분할할 수 있다. 공간을 물리적으로 나누게 되면 프라이머리(primary)라고 부르고, 논리적으로 나누게 되면 익스텐디드(extended)라고 부른다. 그림은 하나의 sd 디스크를 3개의 파티션인 sda1, sda2, sda3로 나눈 것이다.
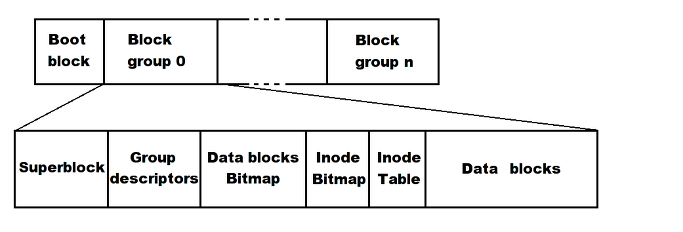
파일 시스템은 각각의 파티션 마다 하나씩 만들어진다. 하나의 파티션에 ext2 파일 시스템을 만들면, 해당 파티션은 여러 개의 block group으로 나뉜다. 부팅에 필요한 정보를 담고 있는 부트스트랩 코드가 존재하는 부트 블록(boot block)은 부팅 시 필요한 부분이기 때문에, 어떤 파일 시스템에서라도 가장 먼저 등장하는 block이다. 기타 block group들은 다시 6가지 부분으로 구분된다:
- 슈퍼 블록(super block)
- 파일 시스템의 전체 크기나 마운트 정보, data block의 개수 등 파일 시스템과 관련된 중요한 정보들을 담고 있음
- 리눅스는 super block의 정보를 사용해 파일 시스템을 관리함
- 다른 block group에 있는 super block도 똑같은 내용을 갖고 있음(사본) - 그룹 디스크립터(group descriptor; GDT)
- 해당 파일 시스템 내의 모든 block group들의 정보를 기록
- super block과 마찬가지로, 다른 block group에 있는 GDT도 똑같은 내용을 갖고 있는 사본임
- group 내의 free block 개수, inode 개수 및 디렉토리 개수 등이 저장되어 있음 - inode 테이블
- 접근권한, 소유주, inode 번호 등 파일에 대한 정보를 저장하고 있는 부분
- 파일 하나 당 하나의 inode가 사용되는데, 이렇게 생성된 모든 inode 번호들이 inode 테이블에 포함되어 있음(파일 시스템이 생성될 때 함께 생성됨) - 데이터 블록 비트맵(data block bitmap)
- data block 내에서의 빈 공간을 관리하기 위해 비트맵을 사용한 것
- block의 할당 상태를 나타내며, block을 할당하거나 해제할 때 사용됨 - inode 비트맵(inode bitmap)
- inode 테이블 내에서의 빈 공간을 관리하기 위해 비트맵을 사용한 것
- (data block bitmap과 비슷하게) inode를 할당하거나 해제할 때 사용됨 - 데이터 블록(data block)
- 실제 데이터의 내용이 저장되는 디스크 영역
참고로 df -i 명령어를 사용해 파일 시스템에서 할당 가능한 inode 개수와 할당되지 않은 inode 개수를 확인할 수 있다.
df -i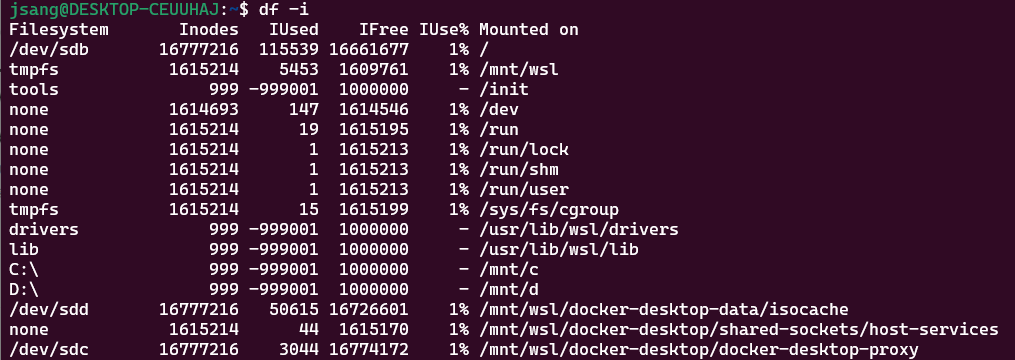
ext2 vs ext3 vs ext4
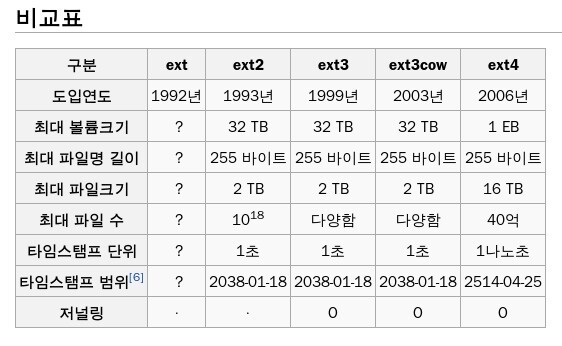
저널링(journaling)은 단연코 ext2와 ext3, ext4를 구분짓는 강력한 기능이라고 할 수 있다. ext3부터는 디스크 안에 별도의 공간인 journal을 통해 파일 시스템의 주요 부분에 아직 commit 되지 않은 변경 사항을 추적할 수 있게 했다. 시스템 충돌 또는 전원 오류(불시에 전원이 나간다거나 하는 오류)가 발생할 경우, 이러한 파일 시스템은 손상될 가능성이 낮아지고 보다 신속하게 온라인 상태로 되돌아올 수 있다(fault tolerant).
ext3에서 지원하는 저널링 모드는 다음 세 가지가 있다.
- Journal - 모든 데이터는 파일 시스템에 쓰여지기 전에 journal에 commit 되고, 나중에 실제 파일 시스템에 복사된다. 속도 측면의 성능은 떨어지지만 가장 높은 안정성을 보장한다.
- Ordered - (ext4 default mode) 데이터는 저널링 없이 기록하고, 메타 데이터만 journal에 기록한다. 비정상 종료시에는 메타 데이터가 journal에 기록되지 않았다면 데이터를 손실할 수 있다.
- Writeback - 데이터를 먼저 저널링하여 기록 후 메타 데이터를 journal에 기록한다. 속도 면에서의 성능은 좋아질 수 있지만, 안정성은 떨어진다.
자료 출처 : https://asfirstalways.tistory.com/145
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kkpa1002&logNo=220246327007
'coding > Linux' 카테고리의 다른 글
| [Linux] 아카이브와 압축 - Archive & Compression (1) | 2022.08.01 |
|---|
